Introduction
In our previous article we saw how to load data into Redshift using SSIS or load data into Redshift using ZappyShell Redshift Command Line
In this article we will walk through various steps to Extract/UNLOAD Redshift Data into SQL Server using Amazon S3 Storage Task and ExecuteSQL Task for Amazon Redshift. Below is the screenshot of actual SSIS Package to Extract Redshift Data and Load into SQL Server
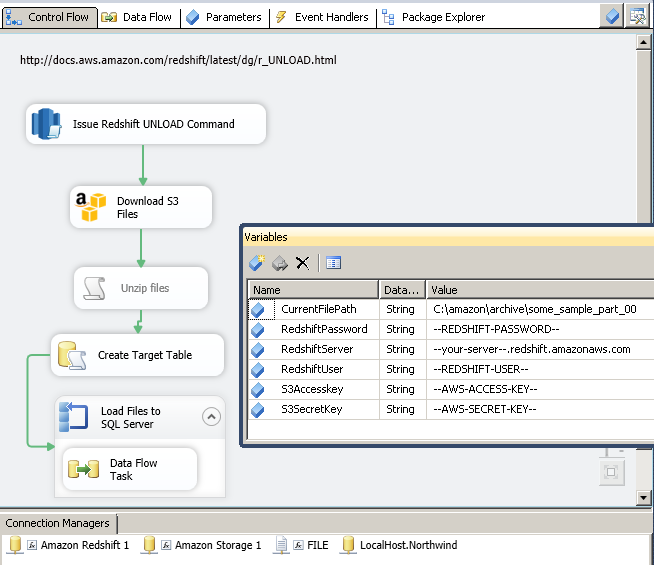
Extract/Unload Redshift Data using SSIS and Load into SQL Server
Requirements for Extract Redshift Data using SSIS
Before you UNLOAD data from Redshift, you have to make sure few things.
- Setup your Redshift cluster (Follow these instructions to setup redshift cluster)
- Load some sample data to Redshift (Red more here: How to load data to Redshift)
- Make sure you have correct connection settings to connect to Redshift cluster (Host name, Port, UserId, Password, DB name etc). You can get host name from AWS Console.
- Make sure you have Access to S3 Bucket where files will be dumped from Redshift. You will need AccessKey and SecretKey to fetch files from S3
Step-1: Execute Redshift UNLOAD Command
Very first step would be to unload redshift data as GZip file using ExecuteSQL Task for Amazon Redshift
Below is SQL Command you can use to extract data from Redshift. Notice how we used variable placeholders in SQL Command. These placeholders are replaced at runtime with actual value stored in specified variable.
|
1 2 3 4 |
unload ('select * from (select * from customerdata limit 1000)') to 's3://bw-rstest/stage/custdata' credentials 'aws_access_key_id={{User::S3Accesskey}};aws_secret_access_key={{User::S3SecretKey}}' ALLOWOVERWRITE |
Export as GZip files (Compressed files)
If you exporting data as compressed files to save data transfer cost then use GZIP option as below.
NOTE: Make sure there are no spaces before and after AccessKey and SecretKey otherwise you may get error.
|
1 2 3 4 5 |
unload ('select * from (select * from customerdata limit 1000)') to 's3://bw-rstest/stage/custdata_file_' credentials 'aws_access_key_id={{User::S3Accesskey}};aws_secret_access_key={{User::S3SecretKey}}' ALLOWOVERWRITE GZIP |
Common Errors / Troubleshooting
UNLOAD command issue with Region mismatch (S3 bucket vs Redshift Cluster)
If your S3 bucket is in different region than Redshift cluster then above command may fail with “301 permanent redirect error” in that case you have to change your S3 bucket region. Region can be changed in AWS console (See S3 bucket properties and change location to match region with Redshift cluster region. Both regions must be same.
ERROR: XX000: S3ServiceException:The bucket you are attempting to access must be addressed using the specified endpoint. Please send all future requests to this endpoint.,Status 301,Error PermanentRedirect
UNLOAD command issue with accesskey and secret key
If you specify invalid accesskey or secretkey –or– you have misspelled keywords related to credentials — or — you have spaces before or after accesskey or secret key then you may get following error.
ERROR: XX000: Invalid credentials. Must be of the format: credentials ‘aws_iam_role=…’ or ‘aws_access_key_id=…;aws_secret_access_key=…[;token=…].
Step-2: Download data files from Amazon S3 Bucket to local machine
Once files are exported to S3 bucket we can download then to local machine using Amazon S3 Storage Task
Step-3: Un-compress downloaded files
If you have exported Redshift data as compressed files (using GZIP option) then you can use ZappySys Zip File task to un-compress multiple files.
Or you can write Script to un-compress those files (see below code). You can skip this step if files are not compressed (not used GZIP option in command).
Here is sample C# code to un-compress GZip files
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
public void Main() { System.IO.DirectoryInfo directorySelected = new System.IO.DirectoryInfo(@"C:\amazon\archive"); foreach (System.IO.FileInfo fileToDecompress in directorySelected.GetFiles("custdata*_part_*")) { Decompress(fileToDecompress); } Dts.TaskResult = (int)ScriptResults.Success; } private static void Decompress(System.IO.FileInfo fileToDecompress) { using (System.IO.FileStream originalFileStream = fileToDecompress.OpenRead()) { string currentFileName = fileToDecompress.FullName; string newFileName = currentFileName.Remove(currentFileName.Length - fileToDecompress.Extension.Length); using (System.IO.FileStream decompressedFileStream = System.IO.File.Create(newFileName)) { using (System.IO.Compression.GZipStream decompressionStream = new System.IO.Compression.GZipStream(originalFileStream, System.IO.Compression.CompressionMode.Decompress)) { decompressionStream.CopyTo(decompressedFileStream); //Console.WriteLine("Decompressed: {0}", fileToDecompress.Name); } } } } |
Step-4: Loop through files using ForEachLoop Container
Once files downloaded from S3 bucket we can now loop through files using SSIS ForEach Loop Task and load into SQL Server (One file in each iteration)
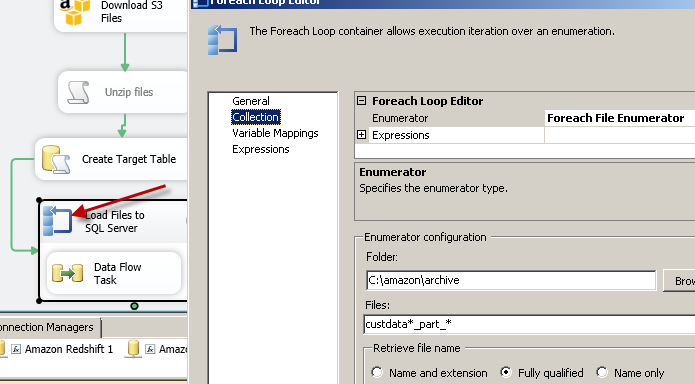
Loop through files downloaded from Amazon S3 (Exported using Redshift UNLOAD Command)
Step-5: Data Flow – Load Redshift Data Files to SQL Server
Inside data flow you can use Flat File source and OLEDB Destination for SQL Server. Just map correct File columns to SQL Server fields and you should be good. If needed convert Unicode/Non-unicode columns using Data Conversion Transform (This is not needed if source is DT_STR and target also DT_STR.. or source is DT_WSTR and target is DT_WSTR i.e. Unicode).
Downloads
To download above SSIS Package click on the below links. In order to test below package you first have to download SSIS PowerPack
Download Demo SSIS Package – SSIS 2008
Download Demo SSIS Package – SSIS 2012/2014
Conclusion
amazon Redshift is great way to start your data warehouse projects with very minimum investment in a very simple pay as you go model but loading or unloading data from redshift can be challenging task. Using SSIS PowerPack you can perform Redshift data load or unload in few clicks.