Introduction
In this blog post you will see how easy it is to load large amount of data from SQL Server to Amazon S3 Storage. For demo purpose we will use SQL Server as relational source but you can use same steps for any database engine such as Oracle, MySQL, DB2. In this post we will use Export CSV Task and Amazon S3 Storage Task to achieve desired integration with Amazon S3 with drag and drop approach. You can also export JSON or XML data to Amazon S3 using same techniques (Use Export JSON Task or Export XML Task ).
Our goal is to achieve following things
- Extract large amount of data from SQL Server Table or Query and export to CSV files
- Generate CSV files in compressed format (*.gz) to speedup upload and save data transfer cost to S3
- Split CSV files by row count
- Upload data to Amazon S3 using highly parallel manner for maximum speed
There are three different ways you can achieve data export to Amazon S3 using SSIS.
- Method-1 (Fastest): Use two step process (First export SQL Server data to local files using Export Task and then upload files to S3 using Amazon S3 Storage Task )
- Method-2 (Slower): Use Export Task with Amazon S3 Connection as Target rather than save to Local files.
- Method-3 (Slower): Use Data flow components like Amazon S3 Destination for CSV (for JSON / XML use Method1 or Method2)
Each method has its own advantage / disadvantage. If you prefer to upload / compress / split large amount of data then we recommend Method#1 (Two steps). If you have not very huge dataset then you can use Method#2 or Method#3. For Last method you can only use CSV export option (we don’t have JSON/ XML Destination for Amazon S3 yet – we may add in future)
Screenshot of SSIS Package
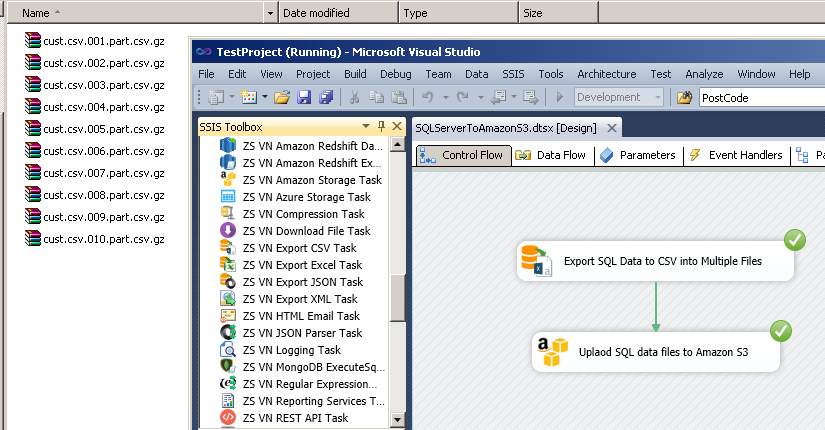
Extract SQL Server Data to CSV files in SSIS (Bulk export) and Split / GZip Compress / upload files to Amazon S3 (AWS Cloud)
Method-1 : Upload SQL data to Amazon S3 in Two steps
In this section we will see first method (recommended) to upload SQL data to Amazon S3. This is the fastest approach if you have lots of data to upload. In this approach we first create CSV files from SQL Server data on local disk using SSIS Export CSV Task. After that in second step we upload all files to Amazon S3 using SSIS Amazon Storage Task.
Step-1: Configure Source Connection in Export CSV Task
To extract data from SQL Server you can use Export CSV Task. It has many options which makes it possible to split large amount of data into multiple files. You can specify single table or multiple tables as your data source.
For multiple table use vertical bar. e.g. dbo.Customers|dbo.Products|dbo.Orders. When you export this it will create 3 files ( dbo.Customers.csv , dbo.Products.csv, dbo.Orders.csv )
Steps:
- Drag ZS Export CSV Task from Toolbox
- Double click task to configure
- From connection drop down select New connection option (OLEDB or ADO.net)
- Once connection is configured for Source database specify SQL Query to extract data as below
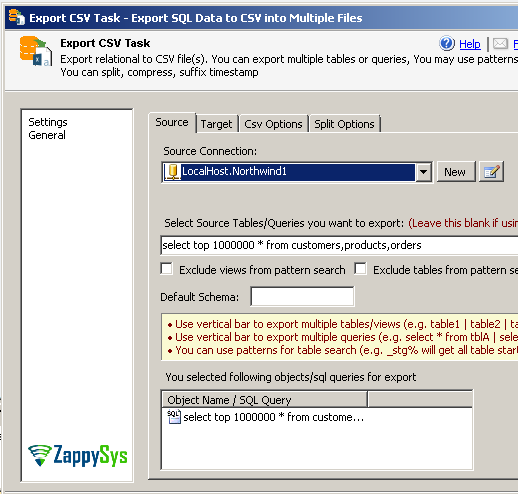
Export SQL Server Table or Query as CSV file (Bulk export in SSIS)
- Now go to target tab. Here you can specify full path for file. e.g. c:\ssis\temp\s3dump\cust.csv
Step-2: Compress CSV Files in SSIS ( GZIP format – *.gz )
Above steps will export file as CSV format without splitting or compression. But to compress file once exported you can go to Target tab of Export CSV Task and check [Compress file to *.gz format] option.
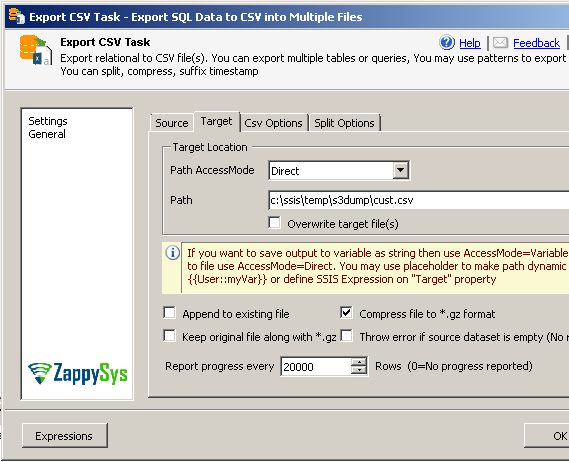
Compress exported SQL Server data files to GZip ( *.gz) in SSIS Export CSV Task
Step-3: Split CSV files by row count or data size in SSIS
Now lets look at how to split exported CSV files into multiple files so we can upload many files in parallel. Goto Split Options and check [Enable Split by Size/Rows]
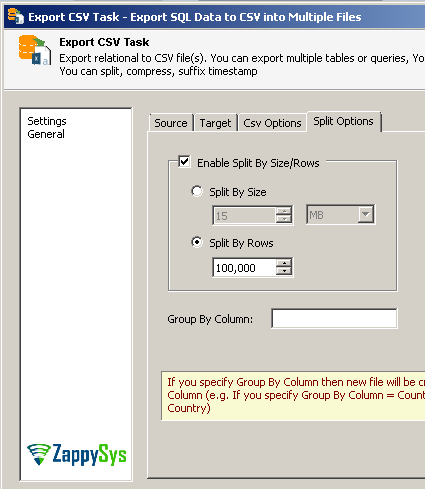
Using SSIS Split Exported CSV files (Split by row count or size)
Step-4: Upload CSV files to Amazon S3 – Using multi threaded option
Now final thing is use Amzon S3 Task to upload files to S3.
Things to remember
Sometimes times due to high network activity you may get timeout errors during upload. In that case you can adjust few settings described here. Also try to reduce total parallel threads on S3 Connection see that helps.
Steps:
- Drag ZS Amazon Storage Task from SSIS toolbox
- Double click Amazon Storage Task to configure it
- Specify Action = UploadFilesToAmazon
- Specify Source file path (or pattern) e.g. c:\SSIS\temp\s3dump\*.*
- Now in the Target connection dropdown click [New]
- When Connection UI opens select Service Type = S3
- Enter your Access Key, Secret Key and Region (Leave all other parameters default if you not sure)
- Click Test and close connection UI
- On the Target path on S3 Storage Task enter your bucket and folder path where you want to upload local files. For example your bucket name is bw-east-1 and folder is sqldata then enter as below
bw-east-1/sqldata/ - Click ok and Run package to test full package
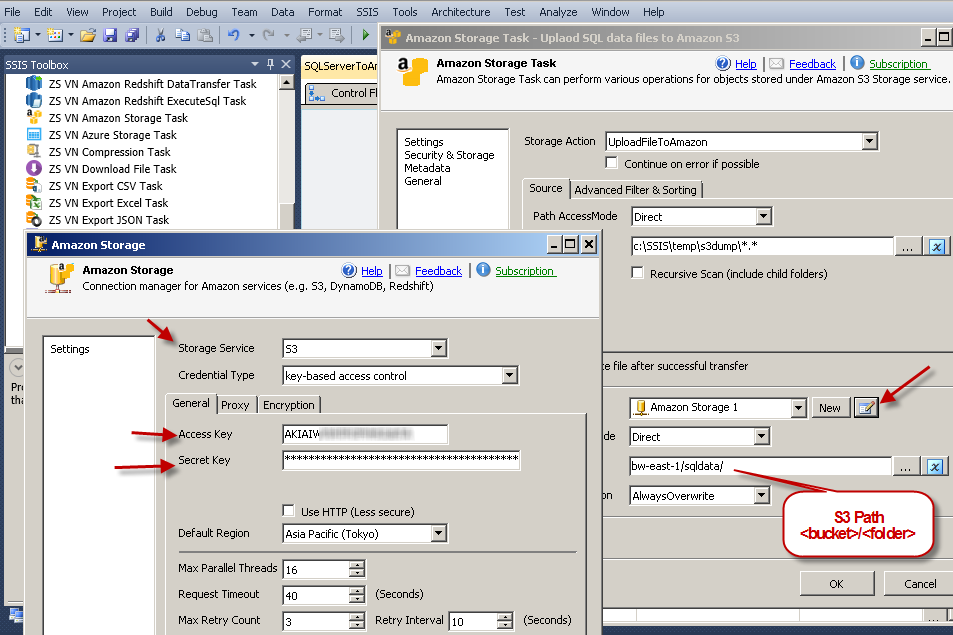
Upload local files to Amazon S3 using SSIS AWS Storage Task
Method-2 : Upload SQL data to Amazon S3 without local stage (One step)
Now let’s change previous approach little bit to send SQL server data directly to Amazon S3 without any Landing area on local disk. Export CSV Task , Export JSON Task and Export XML Task all of them supports Amazon S3 / Azure Blob and Secure FTP (SFTP) connection as target (Only available in Pro Edition). We will use this feature in following section.
This approach helps to avoid any local disk need and it may be useful for security reason for some users. However drawback of this approach is, it wont use parallel threads to upload large amount of data like previous method.
Following change will be needed on Export task to upload SQL data directly to S3 / FTP or Azure storage.
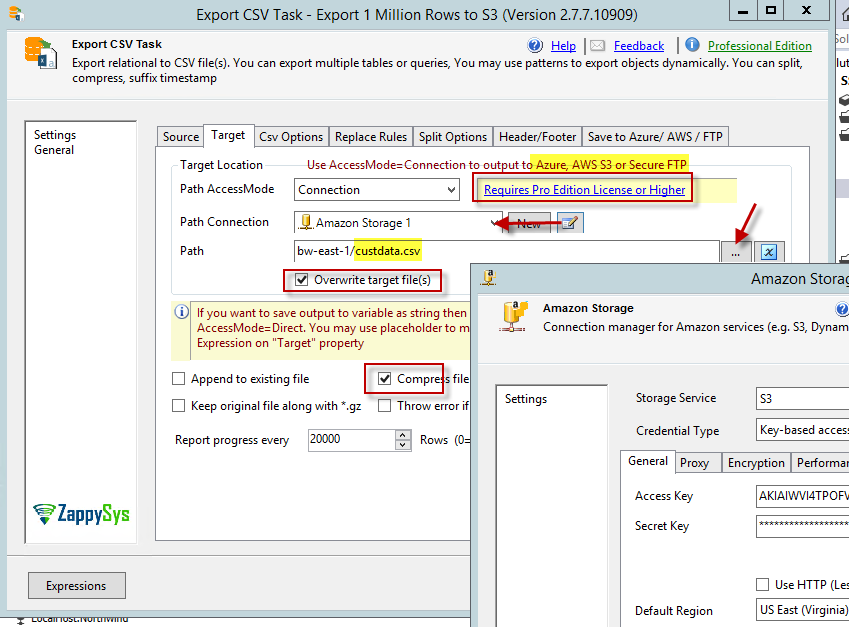
Export SQL data to multiple files to Amazon S3, Azure, Secure FTP (SFTP) in Stream Mode using SSIS. Configure Compress GZip, Overwrite, Split Options
Method-3 : Using Amazon S3 destination – Generate Amazon S3 file from any source
Now let’s look at third approach to save data from any SSIS Source to Amazon S3 file. Advantage of this approach is you are not limited to few source options provided by Export CSV Task. If you have complex data transformation needed in Data Flow before sending data to S3 then use this approach. We will use Amazon S3 Destination for CSV as below
- Drag SSIS Data flow task from toolbox
- Create necessary source connection (e.g. OLEDB connection)
- Create Amazon S3 Connection (Right click in Connection Managers panel in bottom and click New connection and select ZS-AMAZON-STORAGE type )
- Once connection managers are created Go to data flow designer and Drag OLEDB Source
- Configure OLEDB Source to read desired data from source system (e.g. SQL Server / Oracle)
- Once source is configured drag ZS Amazon S3 CSV File Destination from SSIS toolbox
- Double click S3 Destination and configure as below
- On Connection Managers tab select S3 Connection (We created in earlier section).
- Properties tab configure like below screenshot
- On Input Columns tab select desired column you like to write in the target file. Your name from upstream will be taken as is for target file. So make sure to name upstream columns correctly.
- Click OK to save UI
- Execute package and check your S3 Bucket to see files got created.
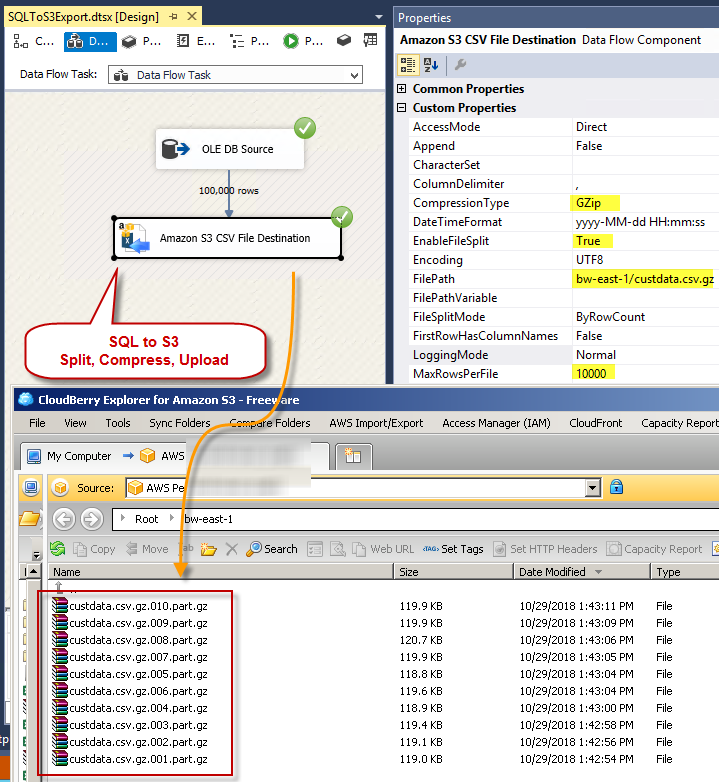
Loading SQL Server data into S3 Bucket Files (Split, Compress Gzip Options) – SSIS Amazon S3 CSV File Destination
Conclusion
In this post you have seen how easy it is to upload / archive your SQL Server data (or any other RDBMS data) to Amazon S3 Storage in few clicks. Try SSIS PowerPack for free and find out yourself how easy it is to integrate SQL Server and Amazon S3 using SSIS.