Problem
Sometimes if you loading data to Redshift via COPY command or using SSIS Redshift Data Transfer Task to move data to redshift then you will have to make sure your S3 Bucket is in the same region as Redshift Cluster. Many people don’t know how to verify that because its hidden in the console. This post will help you to find it easily.
Find Amazon S3 bucket location (AWS Region endpoint)
Below is step-by-step instructions how to find S3 Bucket region (i.e. location)
- Open your AWS Console by visiting https://console.aws.amazon.com/
- From dashboard click on S3 option (or visit https://console.aws.amazon.com/s3/home )
- You will see all buckets in the left side list
- Click on desired S3 bucket name
- Click on Properties Tab at the top
- Now you will see Region for the selected bucket along with many other properties.
Sometimes You may see US Standard as region name that means your bucket is located in US East (N. Virginia)
If you want to know Region Code rather than name check this link : Region Endpoints for Amazon S3
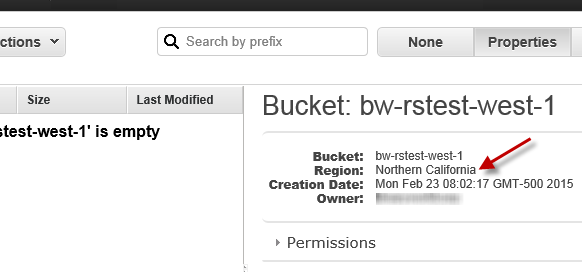
How to find amazon s3 bucket location (AWS region endpoint)
Download/Upload data to S3 bucket via Command line
If you want to automate S3 file download/upload then check this command line tool
ZappyShell Command line tools for Amazon S3

Upload local files to Amazon S3 from command line

List S3 buckets using command line

List S3 file information using command line

List S3 files using command line

Download/Upload data to S3 bucket from SSIS

Load data to Amazon Redshift using S3 Bucket and COPY command
Below video shows how to use S3 bucket to perform bulk data load into Amazon Redshift using SSIS Redshift Data Transfer Task

Conclusion
Amazon S3 provides most common way to store/load data for various AWS related services (e.g. EMR, Redshift). Zappysys is one of the top leading providers who make tools for AWS, NoSQL and other Cloud connectivity providers. Check SSIS PowerPack (For SSIS) or ZappyShell Command line for AWS if you want command line solution. ZappyShell is just single exe file does all heavy lifting for you 🙂
Cheers!