Introduction
In this post we will learn how to fix some metadata / performance related issues in ODBC PowerPack Drivers using Caching / Metadata / Streaming Mode features. By default ZappySys API Drivers issues atleast two API request (First one to obtain Metadata and second, third… for Fetching Data Pages). Most of the times this should be OK and user wont even notice this unless you use tools like fiddler to see how many requests are sent by the driver. Sometimes its necessary to avoid extra requests to obtain metadata (For example you do POST to create a new record or the API has strict Throttling). In this post we will learn various techniques on how to avoid extra POST requests or how to speed up queries by reading from the Cache if your data doesn’t change often.
The Problem
Most of the ZappySys Drivers have metadata detection features (e.g. name, datatype, length, etc.). This is done by reading a few sample rows (around 300 rows – see last section). But this can cause problems in some cases below.
- Slow reading speed due to extra requests needed to scan metadata
- Double requests in POST API call (first meta request and then data request)
Let’s look at how to solve these issues in the following sections.
How to Speedup ZappySys Driver Performance
ZappySys Drivers may provide the following features (Some options may be available only for API drivers). These features can be used to speed up query performance and solve some metadata issues.
- Use Pre-generated Metadata (META option in WITH clause of SQL Query)
- Use Data Caching Option
- Use Streaming Mode for large XML / JSON files
Using Metadata Options in SQL Query
Now let’s talk about Metadata handling. Most ETL / Reporting tool need to know column type, size and precision before getting actual data from driver. If you are dealing with JSON / XML or CSV format you may realize that there is no metadata stored in the file itself to describe columns/data types.
However, metadata must be sent to most Reporting / ETL tool when they use ODBC Driver. ZappySys driver does an intelligent scan from your local file or API response to guess datatypes for each column. In most cases driver does accurate guess but sometimes it’s necessary to adjust metadata (Specially Column Length) to avoid truncation-related errors from your ETL /Reporting tool.
Issue with this automatic metadata scan is, it can be expensive (slow performance) or inaccurate (e.g. invalid datatype for some columns)
Let’s look at how to take complete control on your Metadata so you can avoid metadata-related errors and speed up query performance.
To use metadata you need to perform 3 steps
- Execute a sample query and generate metadata
- Rewrite SQL Query WITH + META to use Metadata captured in the previous step
Generate Metadata Manually
Let’s look at how to generate SQL query metadata using ODBC Driver UI.
- We are assuming you have downloaded and installed ODBC PowerPack
- Open ODBC DSN by typing “ODBC” in your start menu and select ODBC Data Sources 64 bit
- Now create Add and select “ZappySys JSON Driver” for test
- On the UI enter URL like below
1https://services.odata.org/V3/Northwind/Northwind.svc/Invoices?$format=json - Now you can go to the Preview tab and enter query like below and click Preview Data
1select * from value - Once the query is executed you can click Save Metadata button
NOTE: To generate metadata you must run query first else it will throw an error. In some cases, if its not possible (i.e. POST request which creates new records) then you can craft metadata by hand (match attribute name). - You will be prompted with following dialog box. You can choose how to Save metadata and the format of metadata.
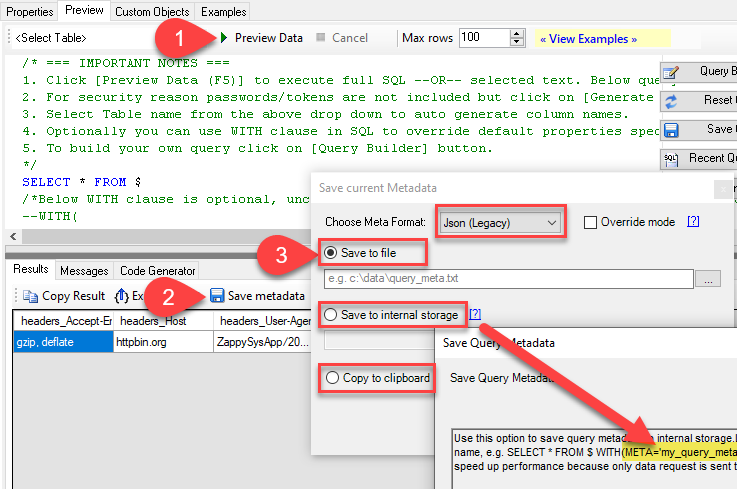
Generate Metadata in ZappySys ODBC Drivers
The metadata file may look like below depending on the sample source URL you used. You can edit this metadata as per your need.
Compact Format (New)
Version 1.4 introduced a new format for metadata. Here is an example. Each pair can be its own line or you can put all in one line. Whitespaces around any value / name is ignored. string type without length assumes 2000 chars long string.
Syntax: col_name1 : type_name[(length)] [; col_name2 : type_name[(length)] ] …. [; col_nameN : type_name[(length)] ]
|
1 2 3 4 5 6 |
col1: int32; col2: string(10); col3: boolean; col4: datetime; col5: int64; col6: double; |
JSON Format (Legacy)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
/* Available column types: Default, String, Int64, Long, Int, Int32, Short, Byte, Decimal, Double, Float, DateTime, Date, Boolean */ [ { "Name": "p_odata_metadata", "Type": "String", "Length": 16777216 }, { "Name": "p_odata_nextLink", "Type": "String", "Length": 16777216 }, { "Name": "ShipName", "Type": "String", "Length": 16777216 }, { "Name": "ShipPostalCode", "Type": "String", "Length": 16777216 }, { "Name": "CustomerID", "Type": "String", "Length": 16777216 }, { "Name": "CustomerName", "Type": "String", "Length": 16777216 }, { "Name": "OrderID", "Type": "Int64", "Length": 16777216 }, { "Name": "OrderDate", "Type": "DateTime", "Length": 16777216 } ] |
Using Metadata in SQL Query
Now it’s time to use Metadata we generated in the previous section and speed up our queries. There are 3 ways you can use metadata in SQL query.
- Metadata as Direct String
- Metadata from file
- Metadata from internal storage
Metadata from Direct String
To use metadata directly inside SQL query using a direct string approach you can use META attribute inside WITH clause as below.
Possible datatypes are: String, Int64, Long, Int, Int32, Short, Byte, Decimal, Double, Float, DateTime, Date, Boolean.
Compact format
|
1 |
select * from value WITH( meta='col1: int32; col2: string(10); col3: boolean; col4: datetime; col5: int64;col6: double' ) |
JSON format (Legacy)
If you are using Legacy Metadata format (JSON) then do below (Just enter Metadata in META attribute like below).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
select * from value WITH( meta='[ { "Name": "p_odata_metadata", "Type": "String", "Length": 16777216 }, { "Name": "p_odata_nextLink", "Type": "String", "Length": 16777216 }, { "Name": "ShipName", "Type": "String", "Length": 16777216 }, ........... ........... ........... ]' ) |
Metadata from File
To use metadata that is saved to a file (like our previous screenshot) use below SQL query for example. The table name may be different in your case if you didn’t use the previous example URL. You can Edit Metadata files as per your need in any text editor.
|
1 |
select * from value WITH( meta='c:\temp\meta.txt' ) |
Metadata from internal DSN Storage
To use metadata that is saved to DSN Storage use below SQL query for example.
|
1 |
select * from value WITH( meta='My-Invoice-Meta' ) |
In the previous section, we mentioned how to Save metadata. In that prompt, the 2nd option is to save metadata to internal DSN Storage. In case you like to see/edit that metadata entry you can do it below way.
Edit Metadata saved to internal DSN Storage
Once you save Metadata to DSN Storage, here is how you can view and edit.
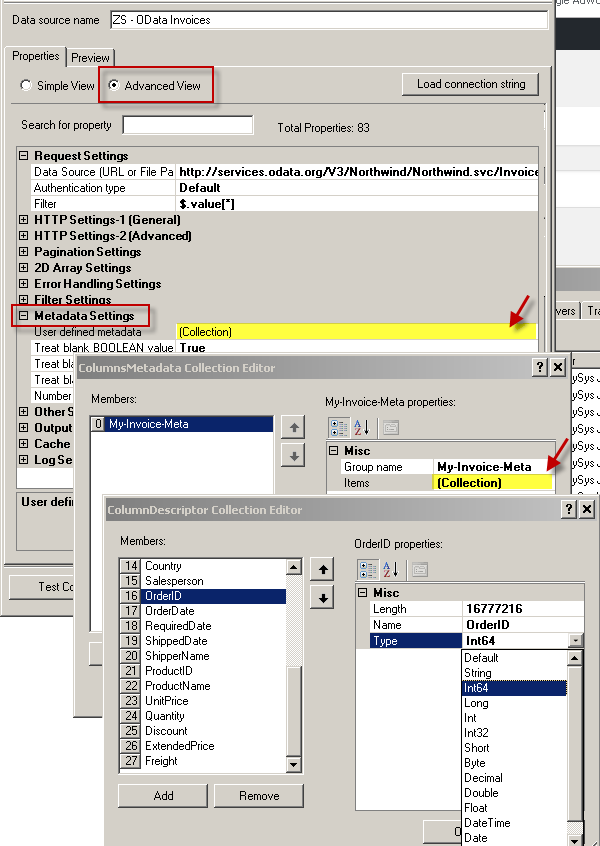
View / Edit Metadata stored in DSN Storage
Hybride Metadata Mode (Auto Scan + Override )
If you have many columns but out of them only some column needs manual override then you can try something like below. This will perform auto scan to detect all columns (let’s say 150 columns) and out of them override datatypes for only two columns (i.e. “id” and “checknumber”).
|
1 |
select * from mytable WITH(META='@OverrideMode:1;id:int;checknumber:string(10)' ) |
or for Legacy format use below
|
1 |
select * from mytable WITH(META='[{Name:"@OverrideMode"}, {Name:"id",Type:"Int32"},{Name:"checknumber",Type:"String",Length:10}]') |
Using Data Caching Options in ODBC Drivers
ZappySys drivers come with very useful Data Caching feature. This can be very useful feature to speed up performance in many cases.
If your data doesn’t change often and you need to issue same query multiple times then enabling data caching may speed up data retrieval significantly. By default ZappySys driver enables Caching for just Metadata (60 Seconds Expiration). So metadata for each query issued by ZappySys Driver is cached for 60 seconds (See below screenshot).
Here is how you can enable caching options.
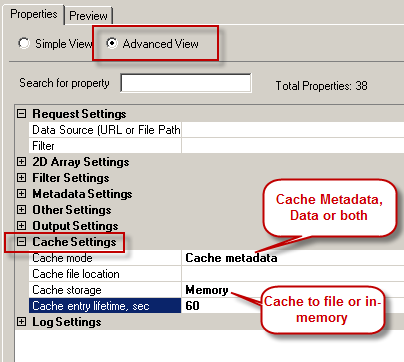
Enable Caching Options for Metadata / Data for ZappySys ODBC Drivers
New version of ODBC PowerPack now supports Caching Options in WITH clause (see below). Per query cache by supplying file name.
|
1 2 3 4 5 6 7 8 |
SELECT * FROM $ WITH ( SRC='https://myhost.com/some-api' ,CachingMode='All' --cache metadata and data rows both ,CacheStorage='File' --or Memory ,CacheFileLocation='c:\temp\myquery.cache' ,CacheEntryTtl=300 --cache for 300 seconds ) |
Using Stream Mode for Large Files
There will be a time when you need to read very large JSON / XML files from local disk or URL. ZappySys engine by default process everything in memory, which may work fine upto certain size but if you have file size larger than OS allowed memory internal limit then you have to tweak some settings.
First lets understand the problem. Try to create new blank DSN and run below query and watch your Memory Graph in Task Manager. You will see RAM graph spikes… and query takes around 10-15 seconds to return 10 rows.
Slow Version (Fully load In memory then parse)
|
1 2 3 4 5 6 7 8 9 |
SELECT * FROM $ LIMIT 10 WITH( Filter='$.LargeArray[*]' ,SRC='https://zappysys.com/downloads/files/test/large_file_100k_largearray_prop.json.gz' --,SRC='c:\data\large_file.json.gz' ,IncludeParentColumns='True' ,FileCompressionType='GZip' --Zip or None (Zip format only available for Local files) ) |
Now let’s modify query little bit. Add –FAST, Turn off IncludeParentColumns and run again below modified query. You will notice it takes less than a second for same result.
FAST Version (Streaming Mode – Parse as you go)
|
1 2 3 4 5 6 7 8 9 |
SELECT * FROM $ LIMIT 10 WITH( Filter='$.LargeArray[*]--FAST' --//Adding --FAST option turn on STREAM mode (large files) ,SRC='https://zappysys.com/downloads/files/test/large_file_100k_largearray_prop.json.gz' --,SRC='c:\data\large_file.json.gz' ,IncludeParentColumns='False' --//This Must be OFF for STREAM mode (read very large files) ,FileCompressionType='GZip' --Zip or None (Zip format only available for Local files) ) |
Understanding Streaming Mode
Now let’s understand step-by-step what we did and why we did. By default if you’re reading JSON / XML data, entire Document is loaded into Memory for processing. This is fine for most cases but some API returns very large Document like below.
Sample JSON File
|
1 2 3 4 5 6 7 8 9 10 |
{ rows:[ {..}, {..}, .... .... 100000 more rows .... {..} ] } |
To read from above document without getting OutOfMemory exception change following settings. For similar problem in SSIS check this article.
- In the filter append –FAST (prefix dash dash)
- Uncheck IncludeParentColumn option (This is needed for stream mode)
- Enable Performance Mode (not applicable for JSON Driver)
- Write your query and execute see how long it takes ( Table name must be $ in FROM clause, Filter must have –FAST suffix, Parent Columns must be excluded as below)
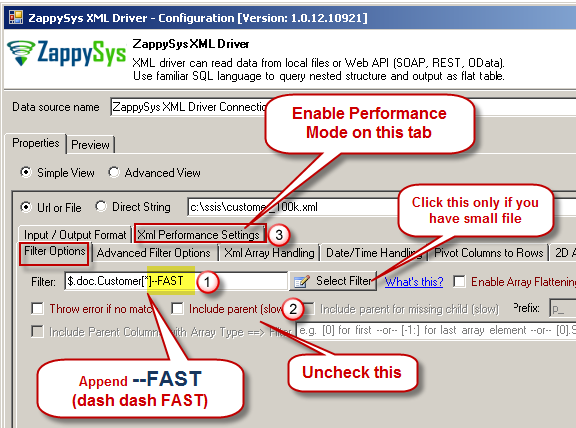
Configure Settings to read very large XML /JSON Files
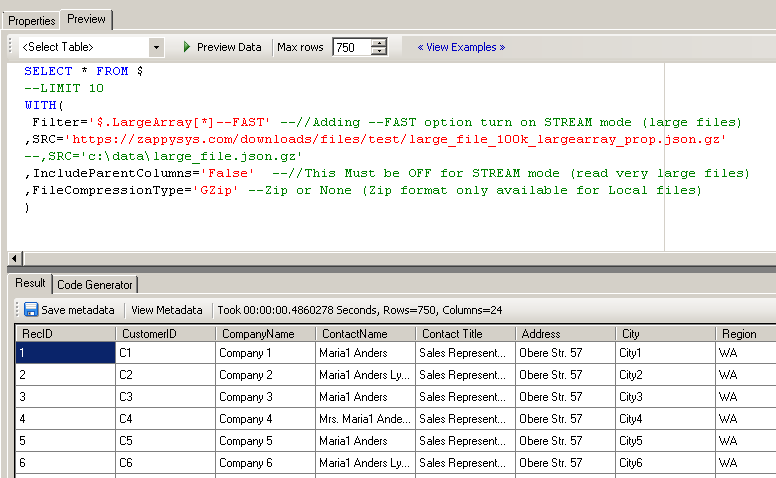
Reading Very Large JSON / XML Files – Streaming Option
SQL Query for reading Large JSON File (Streaming Mode)
Here is a sample query which enables very large JSON file reading using Stream Mode using ZappySys JSON Driver
Notice Three settings.
Table name must be $ in FROM clause, Filter must have –FAST suffix, Parent Columns must be excluded (IncludeParentColumns=false) as below.
|
1 2 3 4 5 6 7 8 9 |
SELECT * FROM $ --LIMIT 10 WITH( Filter='$.LargeArray[*]--FAST' --//Adding --FAST option turn on STREAM mode (large files) ,SRC='https://zappysys.com/downloads/files/test/large_file_100k_largearray_prop.json.gz' --,SRC='c:\data\large_file.json.gz' ,IncludeParentColumns='False' --//This Must be OFF for STREAM mode (read very large files) ,FileCompressionType='GZip' --Zip or None (Zip format only available for Local files) ) |
SQL Query for reading Large XML File (Streaming Mode)
Here is a sample query which enables very large JSON file reading using Stream Mode using ZappySys XML Driver
Notice one extra option EnablePerformanceMode = True for Large XML File Processing and following three changes.
Table name must be $ in FROM clause, Filter must have –FAST suffix, Parent Columns must be excluded (IncludeParentColumns=false) as below.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM $ --LIMIT 10 WITH( Filter='$.doc.Customer[*]--FAST' --//Adding --FAST option turn on STREAM mode (large files) ,SRC='https://zappysys.com/downloads/files/customer_10k.xml' --,SRC='c:\data\customer_10k.xml' ,IncludeParentColumns='False' --//This Must be OFF for STREAM mode (read very large files) ,FileCompressionType='None' --GZip, Zip or None (Zip format only available for Local files) ,EnablePerformanceMode='True' --try to disable this option for simple files ) |
SQL Query for reading large files with parent columns or 2 levels deep
So far we saw one level deep array with Streaming mode. Now assume a scenario where you have a very large XML or JSON file which requires filter more than 2 level deep. (e.g. $.Customers[*].Orders[*] or $.Customers[*].Orders[*].Items[*] ) , and also you need parent columns (e.g. IncludeParentColumns=True).
If you followed previous section, we mentioned that for Streaming mode you must set IncludeParentColumns=False. So what do you do in that case?
Well, you can use JOIN Query as below to support that scenario. You may notice how we extracting Branches for each record and passing to child Query query. Notice that rather than SRC we are using DATA in child query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT a.RecID,a.CustomerID, b.* FROM $ LIMIT 10 WITH( Filter='$.LargeArray[*]--FAST' --//Adding --FAST option turn on STREAM mode (large files) ,SRC='https://zappysys.com/downloads/files/test/large_file_100k_largearray_prop.json.gz' --,SRC='c:\data\large_file.json.gz' ,IncludeParentColumns='False' --//This Must be OFF for STREAM mode (read very large files) ,FileCompressionType='GZip' --Zip or None (Zip format only available for Local files) ,Alias='a' ,JOIN1_Data='[$a.Branches$]' ,JOIN1_Alias='b' ,JOIN1_Filter='' ) |
Enhancing Performance with URL JOIN Queries Using Child Meta Clause
Example Query with URL JOIN
The following query demonstrates how to join two JSON endpoints:
- Customers ( customers.json)
- Orders ( orders-p3.json)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SELECT c.custid, o.orderid, o.orderdate FROM $ WITH( src = 'https://zappysys.com/downloads/files/test/join/customers.json', filter = '$.customers[*]', alias = 'c', -- Joining with Orders endpoint join1_src = 'https://zappysys.com/downloads/files/test/join/c2/orders-p3.json', join1_filter = '$.myArray[*]', join1_alias = 'o', -- Optimized metadata handling (works properly) -- Explicit metadata definition improves performance -- Avoids additional API calls for metadata discovery -- Faster query execution -- join1_meta = 'custid: int64; orderid: int64;orderdate: string(50);' join1_meta = 'C:\temp\meta.txt', ); |
Why Use Explicit Metadata?
- Improved Performance: When the metadata is defined explicitly, the driver skips automatic schema detection, reducing additional API calls.
- Consistency: Prevents mismatched data types and improves query stability.
- Faster Execution: Predefined metadata allows the driver to parse and process data more efficiently.
Handling POST requests to create / update records
As we mention earlier in some cases you might be calling POST requests to Create new records. In such case API request must be sent exactly once. By default Driver sends first request to Get metadata and then sends second request to get data using same parameters used for metadata request. This is usually fine if we reading data and not creating new row on server… (e.g. create new Customer Row). If you have case where you must call API request precisely once then you have to use META clause in the WITH query to avoid Metadata request by supplying static metadata from File or Storage. We discussed this one usecase here.
Advanced Options
Let’s look at some advanced options for metadata management.
Change scan row limit for metadata
By default, Metadata is detected based on scanning 300 rows. But if that scan is inaccurate then you can change the limit by setting the following attribute (this may slow down query performance in some cases).
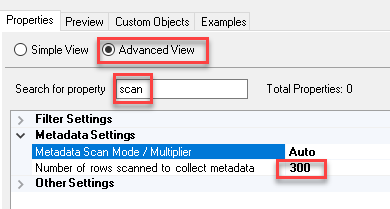
Metadata row scan limit option
Using Disk for Query Processing Engine
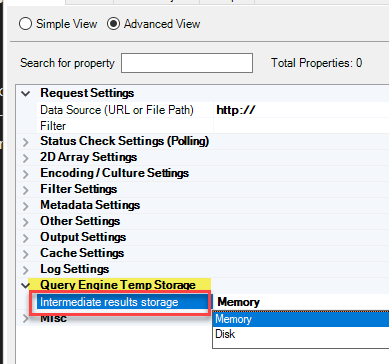
There will be a time when you get OutOfMemory exception due to a large amount of data processed in memory by driver. In such case you instruct the driver to use Disk based temporary engine rather than in-memory using the below option.
- Click on Advanced View
- Goto Query Engine Temp Storage
- Select Disk rather than Memory for “Intermediate results storage“