Introduction
You can connect to your Amazon S3 JSON File data from MS Access via the high-performance Amazon S3 JSON File ODBC Driver. We'll walk you through the entire setup.
Let's not waste time and get started!
Create data source using Amazon S3 JSON File ODBC Driver
Step-by-step instructions
To get data from Amazon S3 JSON File using MS Access, we first need to create an ODBC data source. We will later read this data in MS Access. Perform these steps:
-
Download and install ODBC PowerPack (if you haven't already).
-
Search for
odbcand open the ODBC Data Sources (64-bit):
-
Create a User data source (User DSN) based on the ZappySys Amazon S3 JSON Driver driver:
ZappySys Amazon S3 JSON Driver
- Create and use a User DSN if the client application runs under a User Account. This is the ideal option at design time (e.g., when developing in Visual Studio). Use it for both types of applications (64-bit and 32-bit).
- Create and use a System DSN if the client application runs under a System Account (e.g., as a Windows Service). This is usually the required option in a production environment. If your Windows Service is a 32-bit application, you must use the 32-bit ODBC Data Source Administrator to configure this
-
Create and configure a connection for the Amazon S3 storage account.

-
You can use select your desired single file by clicking [...] path button.
mybucket/dbo.tblNames.jsondbo.tblNames.json
----------OR----------You can also read the multiple files stored in Amazon S3 Storage using wildcard pattern supported e.g. dbo.tblNames*.json.
Note: If you want to operation with multiple files then use wild card pattern as below (when you use wild card pattern in source path then system will treat target path as folder regardless you end with slash) mybucket/dbo.tblNames.json (will read only single .JSON file) mybucket/dbo.tbl*.json (all files starting with file name) mybucket/*.json (all files with .json Extension and located under folder subfolder)
mybucket/dbo.tblNames*.json
----------OR----------You can also read the zip and gzip compressed files also without extracting it in using Amazon S3 JSON Source File Task.
mybucket/dbo.tblNames*.gz")
-
Now select/enter Path expression in Path textbox to extract only specific part of JSON string as below ($.value[*] will get content of value attribute from JSON document. Value attribute is array of JSON documents so we have to use [*] to indicate we want all records of that array)
NOTE: Here, We are using our desired filter, but you need to select your desired filter based on your requirement.
Navigate to the Preview Tab and let's explore the different modes available to access the data.
-
--- Using Direct Query ---
Click on Preview Tab, Select Table from Tables Dropdown and select [value] and click Preview.

-
--- Using Stored Procedure ---
Note : For this you have to Save ODBC Driver configuration and then again reopen to configure same driver. For more information click here.
Click on the Custom Objects Tab, Click on Add button and select Add Procedure and Enter an appropriate name and Click on OK button to create.

-
--- Without Parameters ---
Now Stored Procedure can be created with or without parameters (see example below). If you use parameters then Set default value otherwise it may fail to compilation)

-
--- With Parameters ---
Note : Here you can use Placeholder with Paramters in Stored Procedure. Example : SELECT * FROM $ WHERE OrderID = '<@OrderID, FUN_TRIM>' or CustId = '<@CustId>' and Total >= '<@Total>'

-
-
--- Using Virtual Table ---
Note : For this you have to Save ODBC Driver configuration and then again reopen to configure same driver. For more information click here.
ZappySys APi Drivers support flexible Query language so you can override Default Properties you configured on Data Source such as URL, Body. This way you don't have to create multiple Data Sources if you like to read data from multiple EndPoints. However not every application support supplying custom SQL to driver so you can only select Table from list returned from driver.
Many applications like MS Access, Informatica Designer wont give you option to specify custom SQL when you import Objects. In such case Virtual Table is very useful. You can create many Virtual Tables on the same Data Source (e.g. If you have 50 Buckets with slight variations you can create virtual tables with just URL as Parameter setting).
vt__Customers DataPath=mybucket_1/customers.json vt__Orders DataPath=mybucket_2/orders.json vt__Products DataPath=mybucket_3/products.json
-
Click on the Custom Objects Tab, Click on Add button and select Add Table and Enter an appropriate name and Click on OK button to create.

-
Once you see Query Builder Window on screen Configure it.

-
Click on Preview Tab, Select Virtual Table(prefix with vt__) from Tables Dropdown or write SQL query with Virtual Table name and click Preview.

-
Click on the Custom Objects Tab, Click on Add button and select Add Table and Enter an appropriate name and Click on OK button to create.
-
-
Click OK to finish creating the data source
-
That's it; we are done. In a few clicks we configured the to Read the Amazon S3 JSON File data using ZappySys Amazon S3 JSON File Connector
Read data in Microsoft Access from the ODBC data source
-
First of all, open MS Access and create a new MS Access database.
-
In the next step, start loading ODBC data source we created:

-
Then click next until data source selection window appears. Select the data source we created in one of the previous steps and hit OK:
AmazonS3JsonFileDSN
-
Continue with tables and views selection. You can extract multiple tables or views:

-
Finally, wait while data is being loaded and once done you should see a similar view:

Using Linked Table for Live Data (Slow)
Linked tables in Microsoft Access are crucial for online databases because they enable real-time access to centralized data, support scalability, facilitate collaboration, enhance data security, ease maintenance tasks, and allow integration with external systems. They provide a flexible and efficient way to work with data stored in online databases, promoting cross-platform compatibility and reducing the need for data duplication.
-
Real-Time Data Access:
Access can interact directly with live data in online databases, ensuring that users always work with the most up-to-date information. -
Centralized Data Management:
Online databases serve as a centralized repository, enabling efficient management of data from various locations. -
Ease of Maintenance:
Updates or modifications to the online database structure are automatically reflected in Access, streamlining maintenance tasks. -
Adaptability to Changing Requirements:
Linked tables provide flexibility, allowing easy adaptation to changing data storage needs or migration to different online database systems.
Let's create the linked table.
-
Launch Microsoft Access and open the database where you want to create the linked table.
-
Go to the "External Data" tab on the Ribbon. >> "New Data Source" >> "From Other Sources" >> "ODBC Database"
-
Select the option "Link to Data Source by creating a linked table:

-
Continue by clicking 'Next' until the Data Source Selection window appears. Navigate to the Machine Data Source tab and select the desired data source established in one of the earlier steps. Click 'OK' to confirm your selection.
AmazonS3JsonFileDSN
-
Proceed to the selection of Tables and Views. You have the option to extract multiple tables or views:
-
When prompted to select Unique Key column DO NOT select any column(s) and just click OK:

-
Finally, Simply double-click the newly created Linked Table to load the data:

Guide to Effectively Addressing Known Issues
Discover effective strategies to address known issues efficiently in this guide. Get solutions and practical tips to streamline troubleshooting and enhance system performance, ensuring a smoother user experience.
Fewer Rows Imported
The reason for this is that MS Access has a default query timeout of 60 seconds, which means it stops fetching data if the query takes longer than that. As a result, only a limited number of rows are fetched within this time frame.
To address this, we can adjust the Query Timeout by following the steps below.

The path may vary depending on the MS Access bitness, such as 32-bit versus 64-bit.
\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Jet\4.0\Engines\ODBC
\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Microsoft\Jet\4.0\Engines\ODBC
\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office\ClickToRun\REGISTRY\MACHINE\Software\Microsoft\Office\16.0\Access Connectivity Engine\Engines\ODBC
We can identify this issue by examining the Fiddler Log, as MS Access doesn't display any error regarding partial import, which is quite unusual
Please refer to this link : How to use Fiddler to analyze HTTP web requests

#Deleted word appears for column value in MS Access for Linked Table mode
If you used Linked Table mode to get external data and it shows #deleted word rather than actual value for column after you open then most likely its following issue.
Make sure to re-create Linked Table and DO NOT select any key column when prompted (Just click OK)

How to Fix

Table Selection UI Opening Delays
The Table selection UI takes a significant amount of time to open after clicking the 'New Data Source' -> 'Other Data Sources' -> 'ODBC'
The reason for this issue is that MS Access sends a dummy query, leading to several unnecessary pagination cycles before an error is thrown. To mitigate this, we can prevent wasted cycles by configuring the 'Throw error if no match' setting on the Filter Options Tab.

Enhancing Performance through Metadata Addition (Reduces Query Time)
We can optimize query performance by creating Virtual Tables (i.e. views with custom SQL) on Datasource and incorporating META=static columns. Learn how to capture static metadata in this guide.
Performance Options - Generate Metadata Manually
Execute the query initially, save the metadata by selecting 'Save to Meta' (choose Compact Format), and then click 'Save to Clipboard.' Utilize the resulting list by pasting it into the META attribute as follows: 'META=paste here.'

SELECT * FROM products
WITH(
META='id:String(20); title:String(100); description:String(500);'
)
Optimize Workflow with Automated Import
Employ Automated Import when Linked Tables are not feasible, and we need to depend on Imported Tables with static data.
While using Linked Tables sometime it encounter errors, and we are left with no alternative but to utilize Imported Tables, Automatic Refresh becomes crucial in such scenarios.
Here's a guide on automating refreshes. We can set up automatic refresh on different events, such as when the database opens, a form is opened, or a button is clicked.
To initiate the import process, follow these steps:
- Perform the data import using the standard manual steps.
- In the final step, we'll encounter a checkbox labeled 'Save Import Steps.' Ensure to check this option.
- After saving the steps, we can locate their name in the Save Imports UI. Identify the name associated with the saved steps.
- "Now, we can execute the code as shown below:"
Private Sub cmdYes_Click()
Label0.Visible = True
DoCmd.RunSavedImportExport "Import-DATA.products"
Label0.Visible = False
End Sub
Optional: Centralized data access via ZappySys Data Gateway
In some situations, you may need to provide Amazon S3 JSON File data access to multiple users or services. Configuring the data source on a Data Gateway creates a single, centralized connection point for this purpose.
This configuration provides two primary advantages:
-
Centralized data access
The data source is configured once on the gateway, eliminating the need to set it up individually on each user's machine or application. This significantly simplifies the management process.
-
Centralized access control
Since all connections route through the gateway, access can be governed or revoked from a single location for all users.
| Data Gateway |
Local ODBC
data source
|
|
|---|---|---|
| Simple configuration | ||
| Installation | Single machine | Per machine |
| Connectivity | Local and remote | Local only |
| Connections limit | Limited by License | Unlimited |
| Central data access | ||
| Central access control | ||
| More flexible cost |
To achieve this, you must first create a data source in the Data Gateway (server-side) and then create an ODBC data source in MS Access (client-side) to connect to it.
Let's not wait and get going!
Create Amazon S3 JSON File data source in the gateway
In this section we will create a data source for Amazon S3 JSON File in the Data Gateway. Let's follow these steps to accomplish that:
-
Search for
gatewayin the Windows Start Menu and open ZappySys Data Gateway Configuration:
-
Go to the Users tab and follow these steps to add a Data Gateway user:
- Click the Add button
-
In the Login field enter a username, e.g.,
john - Then enter a Password
- Check the Is Administrator checkbox
- Click OK to save

-
Now we are ready to add a data source:
- Click the Add button
- Give the Data source a name (have it handy for later)
- Then select Native - ZappySys Amazon S3 JSON Driver
- Finally, click OK
AmazonS3JsonFileDSNZappySys Amazon S3 JSON Driver
-
When the ZappySys Amazon S3 JSON Driver configuration window opens, go back to ODBC Data Source Administrator where you already have the Amazon S3 JSON File ODBC data source created and configured, and follow these steps on how to Import data source configuration into the Gateway:
-
Open ODBC data source configuration and click Copy settings:
 ZappySys Amazon S3 JSON Driver - Amazon S3 JSON FileRead and write JSON files in Amazon S3 effortlessly. Streamline, manage, and automate JSON files in S3 buckets for analytics, reporting, and data pipelines — almost no coding required.AmazonS3JsonFileDSN
ZappySys Amazon S3 JSON Driver - Amazon S3 JSON FileRead and write JSON files in Amazon S3 effortlessly. Streamline, manage, and automate JSON files in S3 buckets for analytics, reporting, and data pipelines — almost no coding required.AmazonS3JsonFileDSN
-
The window opens, telling us the connection string was successfully copied to the clipboard:

-
Then go to Data Gateway configuration and in data source configuration window click Load settings:
AmazonS3JsonFileDSN
ZappySys Amazon S3 JSON Driver - Configuration [Version: 2.0.1.10418]ZappySys Amazon S3 JSON Driver - Amazon S3 JSON FileRead and write JSON files in Amazon S3 effortlessly. Streamline, manage, and automate JSON files in S3 buckets for analytics, reporting, and data pipelines — almost no coding required.AmazonS3JsonFileDSN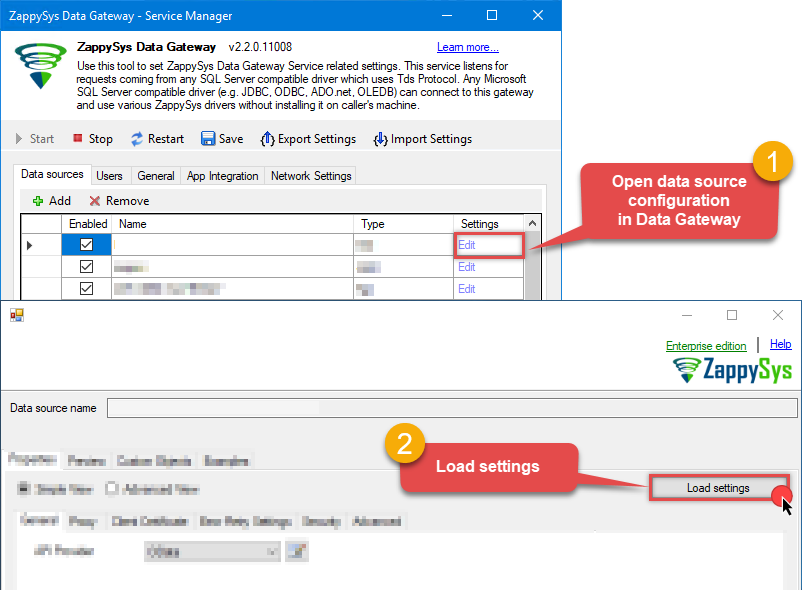
-
Once a window opens, just paste the settings by pressing
CTRL+Vor by clicking right mouse button and then Paste option.
-
Open ODBC data source configuration and click Copy settings:
-
Once done, go to the Network Settings tab and Add a firewall rule for inbound traffic:
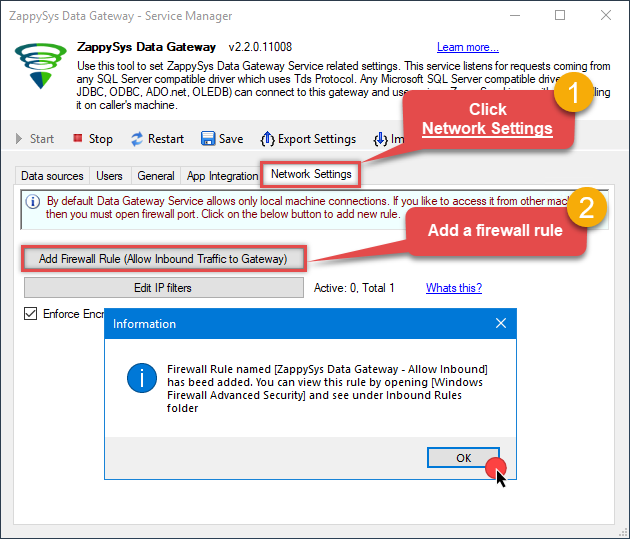
- This will initially allow all inbound traffic.
- Click Edit IP filters to restrict access to specific IP addresses or ranges.
-
Crucial Step: After creating or modifying the data source, you must:
- Click the Save button to persist your changes.
- Hit Yes when prompted to restart the Data Gateway service.
This ensures all changes are properly applied:
 Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Create ODBC data source to connect to the gateway
In this part we will create an ODBC data source to connect to the ZappySys Data Gateway from MS Access. To achieve that, let's perform these steps:
-
Search for
odbcand open the ODBC Data Sources (64-bit):
-
Create a User data source (User DSN) based on the ODBC Driver 17 for SQL Server driver:
ODBC Driver 17 for SQL Server
If you don't see the ODBC Driver 17 for SQL Server driver in the list, choose a similar version. -
Then set a Name for the data source (e.g.
Gateway) and the address of the Data Gateway:ZappySysGatewayDSNlocalhost,5000 Make sure you separate the hostname and port with a comma, e.g.
Make sure you separate the hostname and port with a comma, e.g.localhost,5000. -
Proceed with the authentication part:
- Select SQL Server authentication
-
In the Login ID field enter the user name you created in the Data Gateway, e.g.,
john - Set Password to the one you configured in the Data Gateway

-
Then set the default database property to
AmazonS3JsonFileDSN(the one we used in the Data Gateway):AmazonS3JsonFileDSNAmazonS3JsonFileDSN Make sure to type the data source name manually or copy/paste it directly into the field. Using the dropdown might fail because the Trust server certificate option is not enabled yet (next step).
Make sure to type the data source name manually or copy/paste it directly into the field. Using the dropdown might fail because the Trust server certificate option is not enabled yet (next step). -
Continue by checking the Trust server certificate option:

-
Once you do that, test the connection:

-
If the connection is successful, everything is good:

-
Done!
We are ready to move to the final step. Let's do it!
Access data in MS Access via the gateway
Finally, we are ready to read data from Amazon S3 JSON File in MS Access via the Data Gateway. Follow these final steps:
-
Go back to MS Access.
-
First of all, open MS Access and create a new MS Access database.
-
In the next step, start loading ODBC data source we created:
-
Then click next until data source selection window appears. Select the data source we created in one of the previous steps and hit OK:
ZappySysGatewayDSN
-
Read the data the same way we discussed at the beginning of this article.
-
That's it!
Now you can connect to Amazon S3 JSON File data in MS Access via the ZappySys Data Gateway.
john and your password.
Conclusion
In this guide, we demonstrated how to connect to Amazon S3 JSON File in MS Access and integrate your data — all without writing complex code.
Ready to get started? Download ODBC PowerPack now or ping us via chat if you still need help:


 Connector")







 Connector")













 Connector")





 Connector")




























