Introduction
You can connect to your Amazon S3 XML File data from Microsoft Fabric via the high-performance Amazon S3 XML File ODBC Driver. We'll walk you through the entire setup.
Let's not waste time and get started!
Create data source using Amazon S3 XML File ODBC Driver
Step-by-step instructions
To get data from Amazon S3 XML File using Microsoft Fabric, we first need to create an ODBC data source. We will later read this data in Microsoft Fabric. Perform these steps:
-
Download and install ODBC PowerPack (if you haven't already).
-
Search for
odbcand open the ODBC Data Sources (64-bit):
-
Create a User data source (User DSN) based on the ZappySys Amazon S3 XML Driver driver:
ZappySys Amazon S3 XML Driver
- Create and use a User DSN if the client application runs under a User Account. This is the ideal option at design time (e.g., when developing in Visual Studio). Use it for both types of applications (64-bit and 32-bit).
- Create and use a System DSN if the client application runs under a System Account (e.g., as a Windows Service). This is usually the required option in a production environment. If your Windows Service is a 32-bit application, you must use the 32-bit ODBC Data Source Administrator to configure this
-
Create and configure a connection for the Amazon S3 storage account.

-
You can use select your desired single file by clicking [...] path button.
mybucket/dbo.tblNames.xmldbo.tblNames.xml
----------OR----------You can also read the multiple files stored in Amazon S3 Storage using wildcard pattern supported e.g. dbo.tblNames*.xml.
Note: If you want to operation with multiple files then use wild card pattern as below (when you use wild card pattern in source path then system will treat target path as folder regardless you end with slash) mybucket/dbo.tblNames.xml (will read only single .XML file) mybucket/dbo.tbl*.xml (all files starting with file name) mybucket/*.xml (all files with .xml Extension and located under folder subfolder)
mybucket/dbo.tblNames*.xml
----------OR----------You can also read the zip and gzip compressed files also without extracting it in using Amazon S3 XML Source File Task.
mybucket/dbo.tblNames*.gz")
-
Now select/enter Path expression in Path textbox to extract only specific part of XML string as below ($.value[*] will get content of value attribute from XML document. Value attribute is array of XML documents so we have to use [*] to indicate we want all records of that array)
NOTE: Here, We are using our desired filter, but you need to select your desired filter based on your requirement.
Navigate to the Preview Tab and let's explore the different modes available to access the data.
-
--- Using Direct Query ---
Click on Preview Tab, Select Table from Tables Dropdown and select [value] and click Preview.

-
--- Using Stored Procedure ---
Note : For this you have to Save ODBC Driver configuration and then again reopen to configure same driver. For more information click here.
Click on the Custom Objects Tab, Click on Add button and select Add Procedure and Enter an appropriate name and Click on OK button to create.

-
--- Without Parameters ---
Now Stored Procedure can be created with or without parameters (see example below). If you use parameters then Set default value otherwise it may fail to compilation)

-
--- With Parameters ---
Note : Here you can use Placeholder with Paramters in Stored Procedure. Example : SELECT * FROM $ WHERE OrderID = '<@OrderID, FUN_TRIM>' or CustId = '<@CustId>' and Total >= '<@Total>'

-
-
--- Using Virtual Table ---
Note : For this you have to Save ODBC Driver configuration and then again reopen to configure same driver. For more information click here.
ZappySys APi Drivers support flexible Query language so you can override Default Properties you configured on Data Source such as URL, Body. This way you don't have to create multiple Data Sources if you like to read data from multiple EndPoints. However not every application support supplying custom SQL to driver so you can only select Table from list returned from driver.
Many applications like MS Access, Informatica Designer wont give you option to specify custom SQL when you import Objects. In such case Virtual Table is very useful. You can create many Virtual Tables on the same Data Source (e.g. If you have 50 Buckets with slight variations you can create virtual tables with just URL as Parameter setting).
vt__Customers DataPath=mybucket_1/customers.xml vt__Orders DataPath=mybucket_2/orders.xml vt__Products DataPath=mybucket_3/products.xml
-
Click on the Custom Objects Tab, Click on Add button and select Add Table and Enter an appropriate name and Click on OK button to create.

-
Once you see Query Builder Window on screen Configure it.

-
Click on Preview Tab, Select Virtual Table(prefix with vt__) from Tables Dropdown or write SQL query with Virtual Table name and click Preview.

-
Click on the Custom Objects Tab, Click on Add button and select Add Table and Enter an appropriate name and Click on OK button to create.
-
-
Click OK to finish creating the data source
-
That's it; we are done. In a few clicks we configured the to Read the Amazon S3 XML File data using ZappySys Amazon S3 XML File Connector
Install Microsoft On-premises data gateway (Standard mode)
To access and read Amazon S3 XML File data in Microsoft Fabric, you must download and install the Microsoft On-premises data gateway (Standard mode). It acts as a secure bridge between Microsoft Fabric cloud services and your local Amazon S3 XML File ODBC data source:

There are two types of On-premises data gateways:
- Supports Power BI and other Microsoft Cloud services
- Installs as a Windows service
- Starts automatically
- Supports centralized user access control
- Supports the
Direct Queryfeature - Ideal for enterprise solutions
- Supports Power BI services only
- Cannot run as a Windows service
- Stops when you sign out of Windows
- Does not support access control
- Does not support the
Direct Queryfeature - Best for individual use and POC solutions
You can download the On-premises data gateway directly from the Microsoft Fabric or Power BI portals:
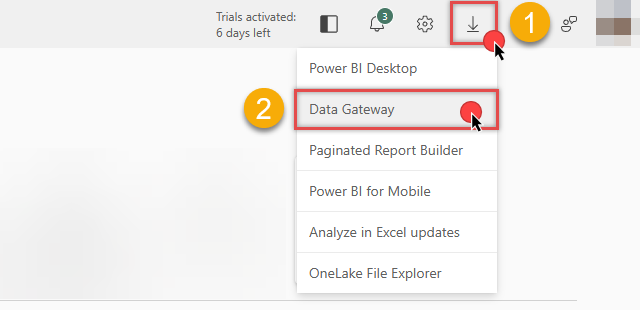
Link ODBC data source via the gateway
Follow these steps to download, install, and configure the gateway in Standard mode:
-
Download On-premises data gateway (standard mode) and run the installer.
-
Once the configuration window opens, sign in:
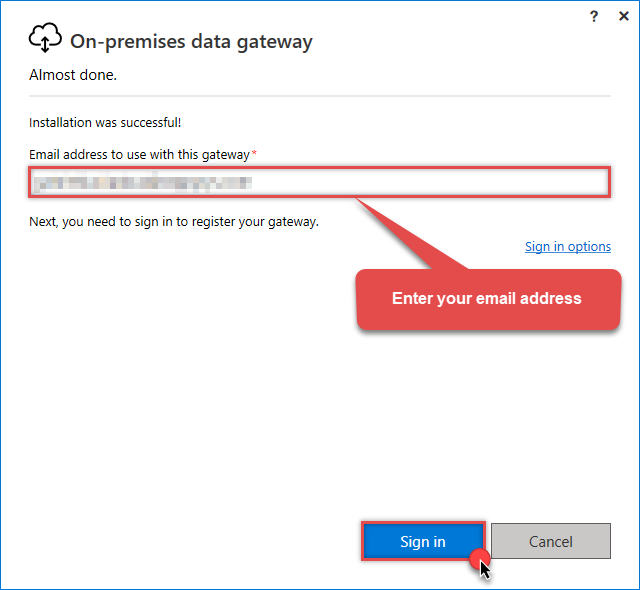 Sign in with the same email address you use for Microsoft Fabric.
Sign in with the same email address you use for Microsoft Fabric. -
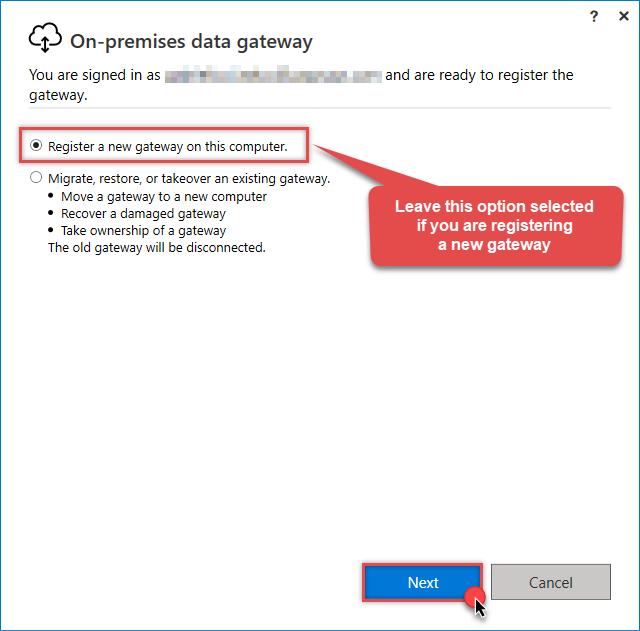
Select Register a new gateway on this computer (or migrate an existing one):
-
Name your gateway, enter a Recovery key, and click the Configure button:
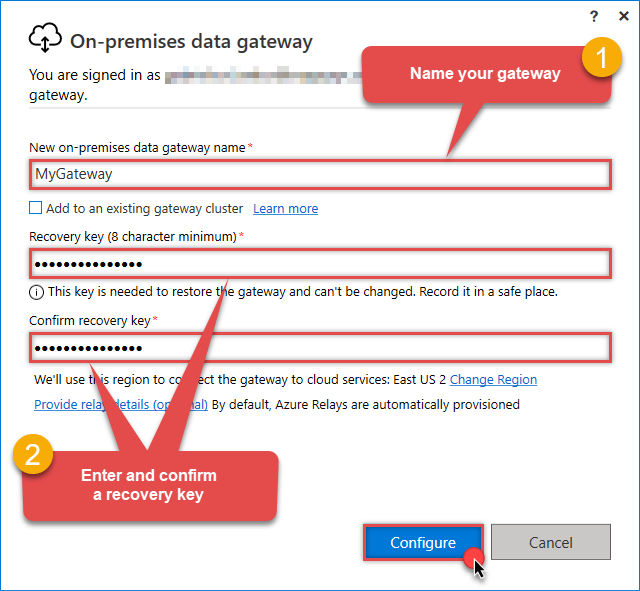 Save your Recovery Key in a safe place (like a password manager). If you lose it, you cannot restore or migrate this gateway later.
Save your Recovery Key in a safe place (like a password manager). If you lose it, you cannot restore or migrate this gateway later. -
Once Microsoft gateway is installed, check if it registered correctly:
-
Go back to Microsoft Fabric portal
-
Click Gear icon on top-right
-
And then hit Manage connections and gateways menu item
-
-
Continue by clicking the On-premises data gateway tab and selecting Standard mode gateways from the dropdown menu:
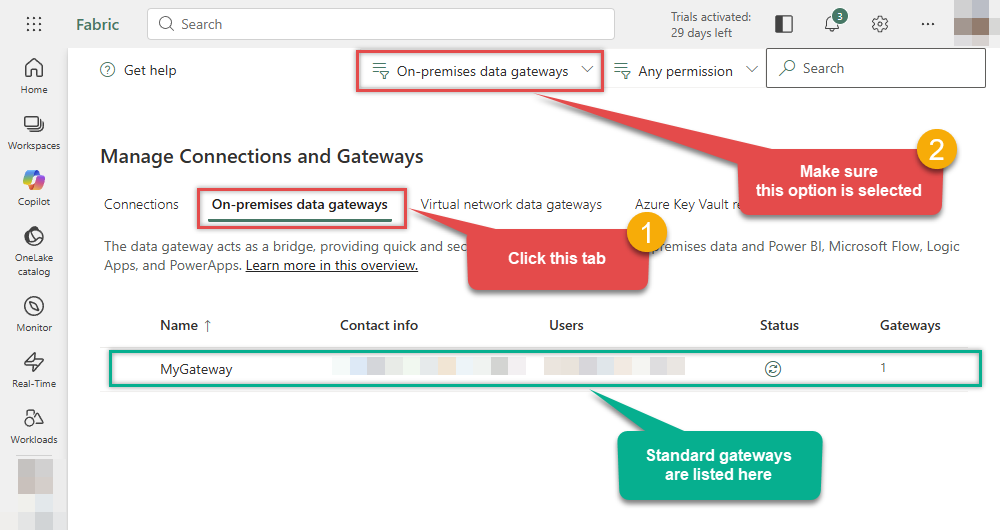
If your gateway is not listed, the registration may have failed. To resolve this:
- Wait a couple of minutes and refresh Microsoft Fabric portal page
- Restart the machine where On-premises data gateway is installed
- Check firewall settings
-
Success! The gateway is now Online and ready to handle requests.
- Done!
You are now ready to load data into Microsoft Fabric.
Load Amazon S3 XML File data into Microsoft Fabric
Now that we have configured the ODBC data source and installed the On-premises data gateway, we can proceed with loading data. You can accomplish this in two ways:
-
Copy job
Best for simple, high-speed data copying without modification.
-
Dataflow Gen2
Best if you need to transform, clean, or reshape data before loading.
Let's dive into the steps for both methods.
Use Copy job for high-speed loading
-
Go to the Microsoft Fabric Portal.
-
Select an existing Workspace or create a new one by clicking New workspace (ensure you are in the Home section):

-
Inside your workspace, click the New item button in the toolbar to start creating your data pipeline:

-
In the item selection window, choose Copy job to open the data ingestion wizard:

-
In the Choose data source screen, search for
odbcand select the Odbc source: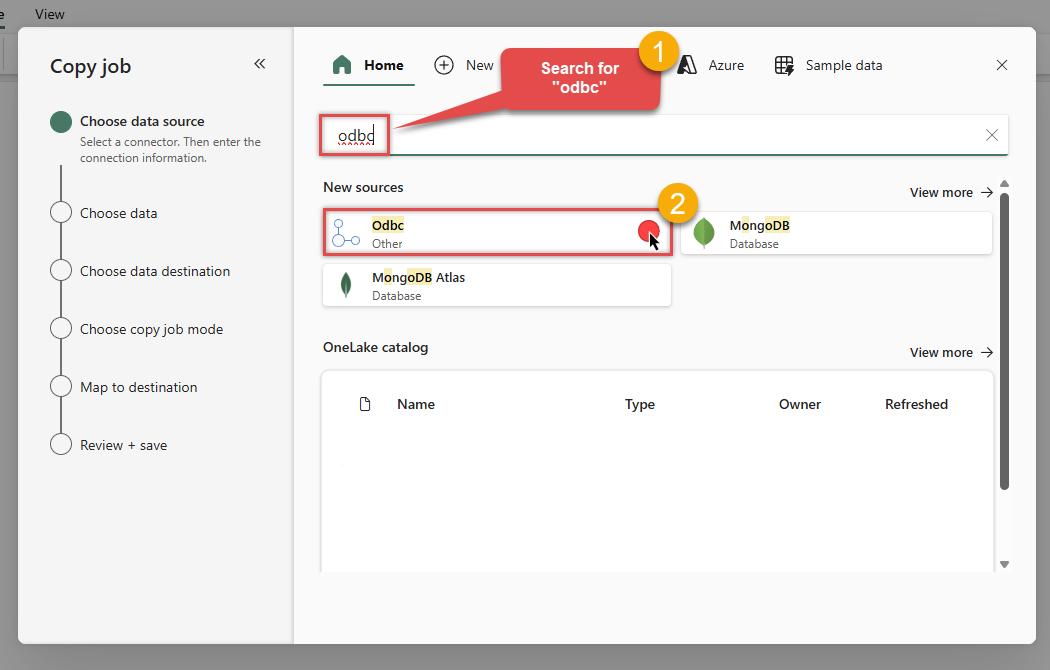
-
Then enter your ODBC connection string (
DSN=AmazonS3XmlFileDSN) and selectMyGatewayfrom the Data gateway dropdown we configured in the previous step:DSN=AmazonS3XmlFileDSNDSN=AmazonS3XmlFileDSN
-
Select the table(s) and preview the data you wish to copy from Amazon S3 XML File. Once done, click Next:
DSN=AmazonS3XmlFileDSN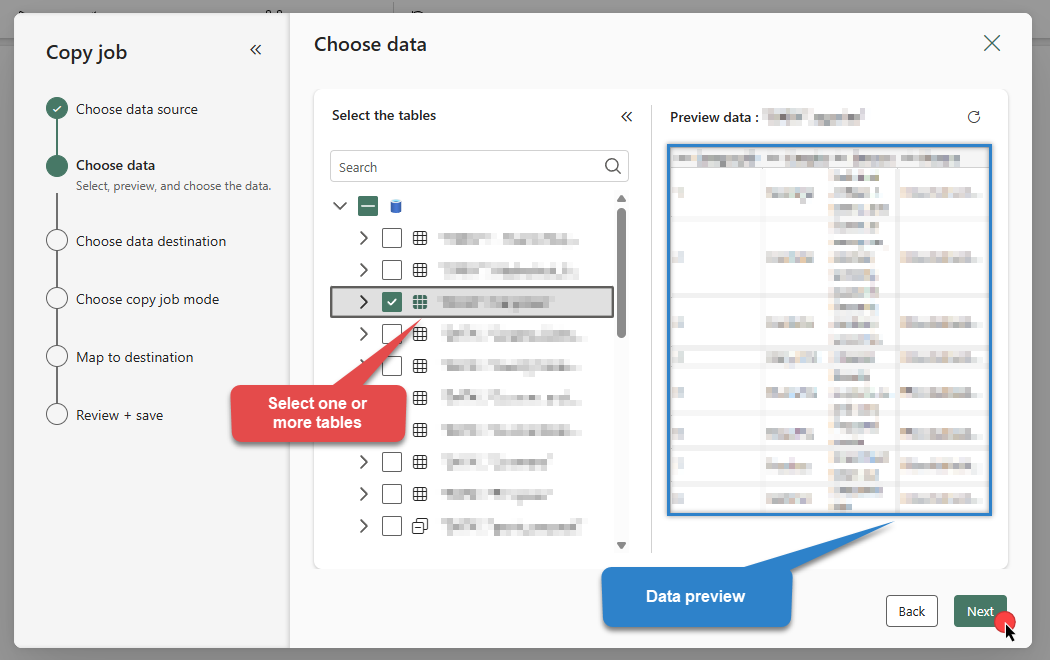
-
Choose your Data Destination. You can create a New Fabric item (like a Lakehouse or Warehouse) or select an existing one:
 In this example, we will use a Lakehouse as the destination.
In this example, we will use a Lakehouse as the destination. -
Choose Full copy to load all data, or Incremental copy to load only changed data in subsequent runs:

-
Review the Column and Table mappings section:

-
On the summary screen, review your settings. You can optionally enable Run on schedule. Click Save + Run to execute the job:
DSN=AmazonS3XmlFileDSNDSN=AmazonS3XmlFileDSN
-
The job will enter the queue. Monitor the Status column to see the progress:
DSN=AmazonS3XmlFileDSN
-
Wait for the status to change to Succeeded. Your Amazon S3 XML File data is now successfully integrated into Microsoft Fabric!

-
Let's go to our Lakehouse (
MyLakehouse) and verify the data:
-
Success! The data has been loaded.
Use Dataflow for advanced transformation
Another way to load data is by creating a Dataflow Gen2. This approach allows you to perform complex data transformations (ETL) before loading the data into its destination.
Configure Dataflow activity
-
Go to the Microsoft Fabric Portal.
-
Inside your workspace, click New item and select Dataflow Gen2:

-
In the Power Query editor, click Get data from another source:

-
Search for ODBC in the search bar and select the ODBC connector:

-
Then in the next step follow these instructions:
-
Enter your ODBC connection string (e.g.,
DSN=AmazonS3XmlFileDSN) - Expand Advanced options
- Enter your SQL statement
- Select your On-premises data gateway
- Finally, click Next:
DSN=AmazonS3XmlFileDSNDSN=AmazonS3XmlFileDSNSELECT * FROM Orders
-
Enter your ODBC connection string (e.g.,
-
You will see a preview of your Amazon S3 XML File data. You can now transform the data if needed (filter rows, rename columns, change types, etc.):
Odbc.Query("DSN=AmazonS3XmlFileDSN", "SELECT * FROM Orders")
-
Now, let's send this data to the Lakehouse. Click the + button (Add data destination) at the bottom right and select Lakehouse:
Odbc.Query("DSN=AmazonS3XmlFileDSN", "SELECT * FROM Orders")
-
Configure the destination connection settings and click Next:

-
Select your specific Lakehouse, enter the Table name you want to create, and click Next:

-
Uncheck Use automatic settings to set data update or schema options manually. Map the columns with proper data types and click Save settings when done:

-
The destination is now set. Click the Publish button to save the Dataflow:
Odbc.Query("DSN=AmazonS3XmlFileDSN", "SELECT * FROM Orders")
-
Done! You can now start building reports using your new semantic model.
Configure and run Pipeline
Once you have created and published your Dataflow, you can use a Pipeline to orchestrate and run it.
-
Go to the Microsoft Fabric Portal.
-
Inside your workspace, click New item and select Data Pipeline to create a new pipeline.

-
In the pipeline editor, select the Dataflow activity from the toolbar to add it to your canvas:

-
Select the Dataflow activity on the canvas and click the Settings tab. Choose your Workspace and the Dataflow you created in the previous steps:

-
You are now ready to link the Dataflow with other Pipeline activities.
-
Once the Pipeline flow is configured, click the Run button at the top, then click Save and run to execute the pipeline:

-
Monitor the Output tab below. The Pipeline status will initially show as In progress:

-
Wait for the process to complete. The status will update to Succeeded, indicating your data has been successfully loaded via the Dataflow:

-
Done! You can now start building reports on your new semantic model.
Optional: Centralized data access via ZappySys Data Gateway
In some situations, you may need to provide Amazon S3 XML File data access to multiple users or services. Configuring the data source on a Data Gateway creates a single, centralized connection point for this purpose.
This configuration provides two primary advantages:
-
Centralized data access
The data source is configured once on the gateway, eliminating the need to set it up individually on each user's machine or application. This significantly simplifies the management process.
-
Centralized access control
Since all connections route through the gateway, access can be governed or revoked from a single location for all users.
| Data Gateway |
Local ODBC
data source
|
|
|---|---|---|
| Simple configuration | ||
| Installation | Single machine | Per machine |
| Connectivity | Local and remote | Local only |
| Connections limit | Limited by License | Unlimited |
| Central data access | ||
| Central access control | ||
| More flexible cost |
To achieve this, you must first create a data source in the Data Gateway (server-side) and then create an ODBC data source in Microsoft Fabric (client-side) to connect to it.
Let's not wait and get going!
Create Amazon S3 XML File data source in the gateway
In this section we will create a data source for Amazon S3 XML File in the Data Gateway. Let's follow these steps to accomplish that:
-
Search for
gatewayin the Windows Start Menu and open ZappySys Data Gateway Configuration:
-
Go to the Users tab and follow these steps to add a Data Gateway user:
- Click the Add button
-
In the Login field enter a username, e.g.,
john - Then enter a Password
- Check the Is Administrator checkbox
- Click OK to save

-
Now we are ready to add a data source:
- Click the Add button
- Give the Data source a name (have it handy for later)
- Then select Native - ZappySys Amazon S3 XML Driver
- Finally, click OK
AmazonS3XmlFileDSNZappySys Amazon S3 XML Driver
-
When the ZappySys Amazon S3 XML Driver configuration window opens, go back to ODBC Data Source Administrator where you already have the Amazon S3 XML File ODBC data source created and configured, and follow these steps on how to Import data source configuration into the Gateway:
-
Open ODBC data source configuration and click Copy settings:
 ZappySys Amazon S3 XML Driver - Amazon S3 XML FileRead and write XML files in Amazon S3 effortlessly. Streamline, manage, and automate XML files in S3 buckets for analytics, reporting, and data pipelines — almost no coding required.AmazonS3XmlFileDSN
ZappySys Amazon S3 XML Driver - Amazon S3 XML FileRead and write XML files in Amazon S3 effortlessly. Streamline, manage, and automate XML files in S3 buckets for analytics, reporting, and data pipelines — almost no coding required.AmazonS3XmlFileDSN
-
The window opens, telling us the connection string was successfully copied to the clipboard:

-
Then go to Data Gateway configuration and in data source configuration window click Load settings:
AmazonS3XmlFileDSN
ZappySys Amazon S3 XML Driver - Configuration [Version: 2.0.1.10418]ZappySys Amazon S3 XML Driver - Amazon S3 XML FileRead and write XML files in Amazon S3 effortlessly. Streamline, manage, and automate XML files in S3 buckets for analytics, reporting, and data pipelines — almost no coding required.AmazonS3XmlFileDSN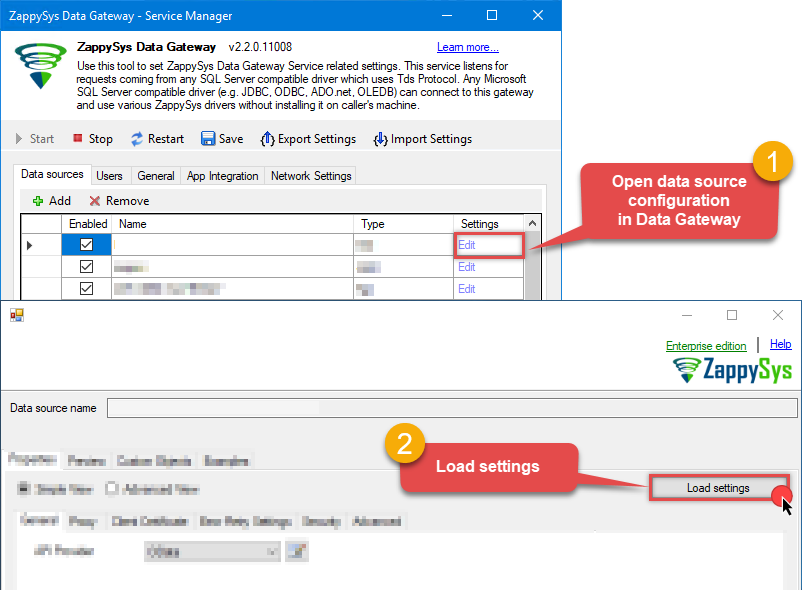
-
Once a window opens, just paste the settings by pressing
CTRL+Vor by clicking right mouse button and then Paste option.
-
Open ODBC data source configuration and click Copy settings:
-
Once done, go to the Network Settings tab and Add a firewall rule for inbound traffic:
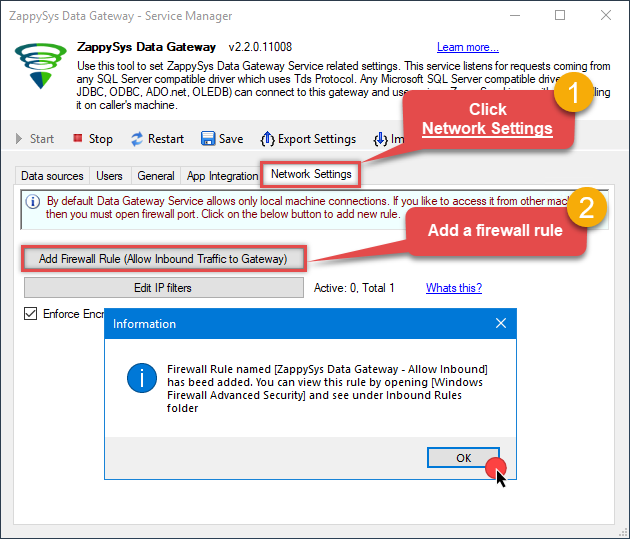
- This will initially allow all inbound traffic.
- Click Edit IP filters to restrict access to specific IP addresses or ranges.
-
Crucial Step: After creating or modifying the data source, you must:
- Click the Save button to persist your changes.
- Hit Yes when prompted to restart the Data Gateway service.
This ensures all changes are properly applied:
 Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Create ODBC data source to connect to the gateway
In this part we will create an ODBC data source to connect to the ZappySys Data Gateway from Microsoft Fabric. To achieve that, let's perform these steps:
-
Search for
odbcand open the ODBC Data Sources (64-bit):
-
Create a User data source (User DSN) based on the ODBC Driver 17 for SQL Server driver:
ODBC Driver 17 for SQL Server
If you don't see the ODBC Driver 17 for SQL Server driver in the list, choose a similar version. -
Then set a Name for the data source (e.g.
Gateway) and the address of the Data Gateway:ZappySysGatewayDSNlocalhost,5000 Make sure you separate the hostname and port with a comma, e.g.
Make sure you separate the hostname and port with a comma, e.g.localhost,5000. -
Proceed with the authentication part:
- Select SQL Server authentication
-
In the Login ID field enter the user name you created in the Data Gateway, e.g.,
john - Set Password to the one you configured in the Data Gateway

-
Then set the default database property to
AmazonS3XmlFileDSN(the one we used in the Data Gateway):AmazonS3XmlFileDSNAmazonS3XmlFileDSN Make sure to type the data source name manually or copy/paste it directly into the field. Using the dropdown might fail because the Trust server certificate option is not enabled yet (next step).
Make sure to type the data source name manually or copy/paste it directly into the field. Using the dropdown might fail because the Trust server certificate option is not enabled yet (next step). -
Continue by checking the Trust server certificate option:

-
Once you do that, test the connection:

-
If the connection is successful, everything is good:

-
Done!
We are ready to move to the final step. Let's do it!
Access data in Microsoft Fabric via the gateway
Finally, we are ready to read data from Amazon S3 XML File in Microsoft Fabric via the Data Gateway. Follow these final steps:
-
Go back to Microsoft Fabric.
-
Then, go to your Copy job or Dataflow and start configuring your ODBC data source (like you did in the previous step).
-
In the ODBC configuration window, configure these fields:
-
Enter your ODBC connection string (DSN format), for example:
DSN=ZappySysGatewayDSN - Expand Advanced options and set the SQL statement
-
Select
MyGatewayfrom the Data gateway dropdown that you configured in the previous step -
Select
Basicfrom the Authentication kind dropdown -
Enter the Username (e.g.,
john) and Password that you configured in ZappySys Data Gateway
DSN=ZappySysGatewayDSNSELECT * FROM Orders
DSN=ZappySysGatewayDSN
-
Enter your ODBC connection string (DSN format), for example:
-
Read the data the same way we discussed at the beginning of this article.
-
That's it!
Now you can connect to Amazon S3 XML File data in Microsoft Fabric via the ZappySys Data Gateway.
Conclusion
In this guide, we demonstrated how to connect to Amazon S3 XML File in Microsoft Fabric and integrate your data — all without writing complex code.
Ready to get started? Download ODBC PowerPack now or ping us via chat if you still need help:


 Connector")







 Connector")













 Connector")





 Connector")




























