

Introduction
You can connect to your Apache Spark data from Java via the high-performance Apache Spark ODBC Driver (powered by ZappySys JDBC-ODBC Bridge Driver). We'll walk you through the entire setup.
Let's not waste time and get started!
Prerequisites
Before we begin, make sure you meet the following prerequisite: Java Runtime Environment (JRE) or Java Development Kit (JDK) must be installed on your system.
-
Minimum required version: Java 8
-
Recommended Java version: Java 21
If your JDBC Driver targets a different Java version (e.g., 11 / 17 / 21), install the corresponding or newer Java version.
Download Apache Spark JDBC driver
To connect to Apache Spark, you will have to download JDBC driver for it, which we will use in later steps. Let's perform these little steps right away:
-
Visit MVN Repository.
-
Select the appropriate JDBC driver version in Latest Versions section in MVN Repository:
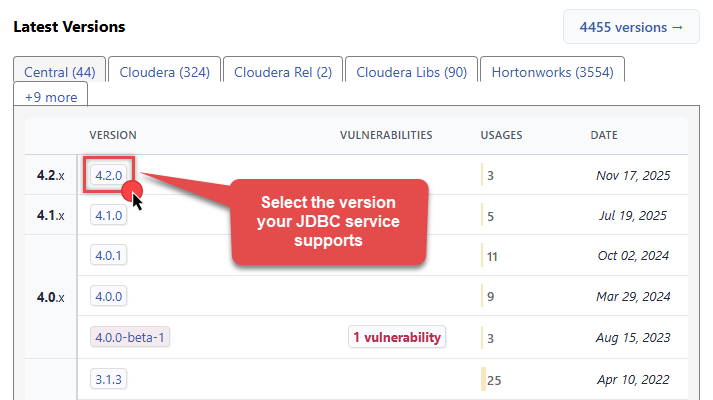
-
Download the JDBC driver, and save it locally, e.g. to
D:\Drivers\JDBC\hive-jdbc-standalone.jar.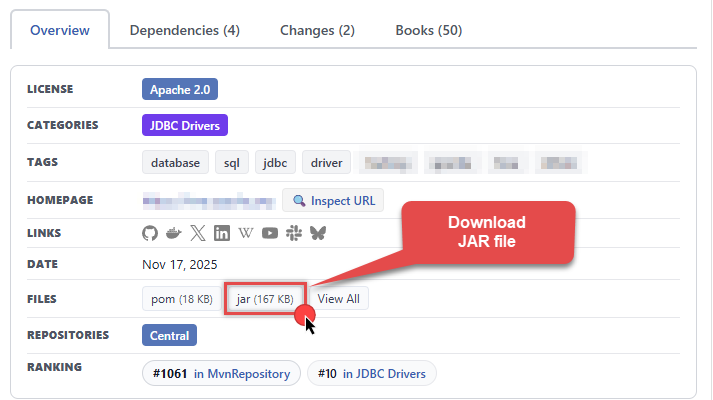
- Make sure to download the standalone version of the Apache Hive JDBC driver to avoid Java library dependency errors, e.g., hive-jdbc-4.0.1-standalone.jar (commonly used driver to connect to Spark).
-
Done! That was easy, wasn't it? Let's proceed to the next step.
Create data source in ZappySys Data Gateway
In this section we will create a data source for Apache Spark in the Data Gateway. Let's follow these steps to accomplish that:
-
Download and install ODBC PowerPack (if you haven't already).
-
Search for
gatewayin the Windows Start Menu and open ZappySys Data Gateway Configuration:
-
Go to the Users tab and follow these steps to add a Data Gateway user:
- Click the Add button
-
In the Login field enter a username, e.g.,
john - Then enter a Password
- Check the Is Administrator checkbox
- Click OK to save

-
Now we are ready to add a data source:
- Click the Add button
- Give the Data source a name (have it handy for later)
- Then select Native - ZappySys JDBC Bridge Driver
- Finally, click OK
ApacheSparkDSNZappySys JDBC Bridge Driver
-
Now, we need to configure the JDBC connection in the new ODBC data source. Simply enter the Connection string, credentials, configure other settings, and then click Test Connection button to test the connection:
ApacheSparkDSNjdbc:hive2://spark-thrift-server-host:10000optional for Apache SparkD:\Drivers\JDBC\hive-jdbc-standalone.jaroptional for Apache Sparkoptional for Apache Spark[]
Use these values when setting parameters:
-
Connection string :jdbc:hive2://spark-thrift-server-host:10000 -
JDBC driver file(s) :D:\Drivers\JDBC\hive-jdbc-standalone.jar -
Connection parameters :[]
-
-
You should see a message saying that connection test is successful:

-
Otherwise, if you are getting an error, start by troubleshooting the JDBC connection with DBeaver in the section below:
-
We are at the point where we can preview a SQL query. For more SQL query examples visit JDBC Bridge documentation:
ApacheSparkDSN-- Basic SELECT with a WHERE clause SELECT id, name, salary FROM employees WHERE department = 'Sales';
-- Basic SELECT with a WHERE clause SELECT id, name, salary FROM employees WHERE department = 'Sales';You can also click on the <Select Table> dropdown and select a table from the list.The ZappySys JDBC Bridge Driver acts as a transparent intermediary, passing SQL queries directly to the JDBC driver, which then handles the query execution. This means the JDBC-ODBC Bridge Driver simply relays the SQL query without altering it.
Some JDBC drivers don't support
INSERT/UPDATE/DELETEstatements, so you may get an error saying "action is not supported" or a similar one. Please, be aware, this is not the limitation of ZappySys JDBC Bridge Driver, but is a limitation of the specific JDBC driver you are using. -
Click OK to finish creating the data source.
-
Once done, go to the Network Settings tab and Add a firewall rule for inbound traffic:
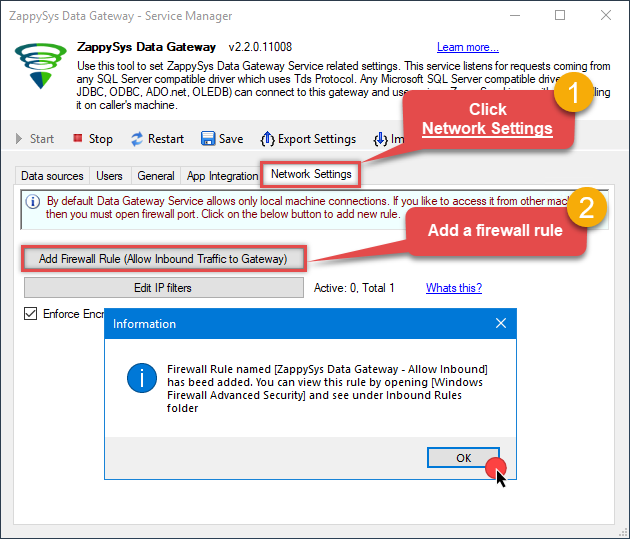
- This will initially allow all inbound traffic.
- Click Edit IP filters to restrict access to specific IP addresses or ranges.
-
Crucial Step: After creating or modifying the data source, you must:
- Click the Save button to persist your changes.
- Hit Yes when prompted to restart the Data Gateway service.
This ensures all changes are properly applied:
 Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Read data in Java from the DSN
-
Java code to get the data:
"jdbc:sqlserver://localhost:5000;databasename=ApacheSparkDSN;user=john;password=test"
-
When you run the code it will make the API call and read the data:

-
Here is Java program's code in text format:
//Step-1: Install ZappySys ODBC PowerPack and Configure Data Gateway //Step-2:Assuming the Microsoft SQL Server JDBC Driver is in below folder //C:\Program Files\Microsoft Jdbc Driver 6.0 for SQL Server\sqljdbc_6.0\enu\auth\x64 package padaone; import java.sql.*; public class zappy { public static void main(String[] args) { // Create a variable for the connection string. String connectionUrl = "jdbc:sqlserver://localhost:5000;databasename=ApacheSparkDSN;user=test;password=test"; // Declare the JDBC objects. Connection con = null; Statement stmt = null; ResultSet rs = null; try { // Establish the connection. Class.forName("com.microsoft.sqlserver.jdbc.SQLServerDriver"); con = DriverManager.getConnection(connectionUrl); // Create and execute an SQL statement that returns some data. String SQL = "SELECT Country , SUM(UnitPrice * Quantity) Total " + "FROM value " + "GROUP BY Country " + "WITH (SRC='https://services.odata.org/V3/Northwind/Northwind.svc/Invoices?$format=json')"; stmt = con.createStatement(); rs = stmt.executeQuery(SQL); // Iterate through the data in the result set and display it. while (rs.next()) { System.out.println(rs.getString(1) + " " + rs.getString(2)); } } // Handle any errors that may have occurred. catch (Exception e) { e.printStackTrace(); } finally { if (rs != null) try { rs.close(); } catch (Exception e) {} if (stmt != null) try { stmt.close(); } catch (Exception e) {} if (con != null) try { con.close(); } catch (Exception e) {} } } }
Troubleshooting
Validating JDBC connection in DBeaver
If you are experiencing JDBC connection issues, start by testing your JDBC driver in a JDBC client tool like DBeaver. If the JDBC connection fails in DBeaver, it naturally will not work in your ODBC data source either.
Create generic JDBC driver
-
Download and install DBeaver Community Edition.
-
Open DBeaver.
-
Click Database in the top menu and select Driver Manager:
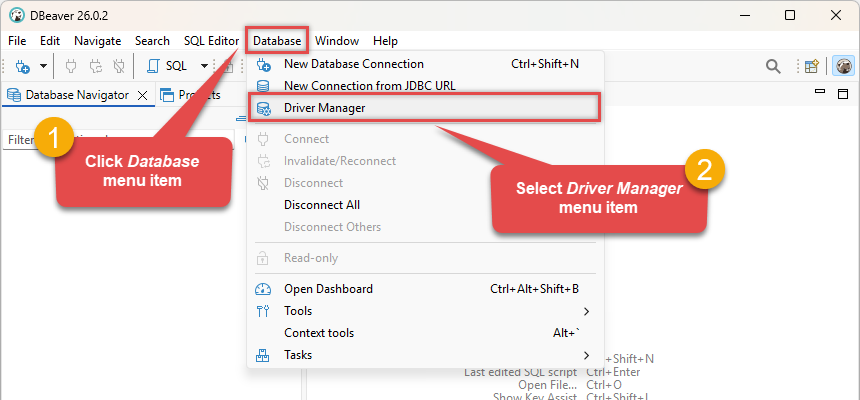
-
Click the New button to start adding a custom JDBC driver:
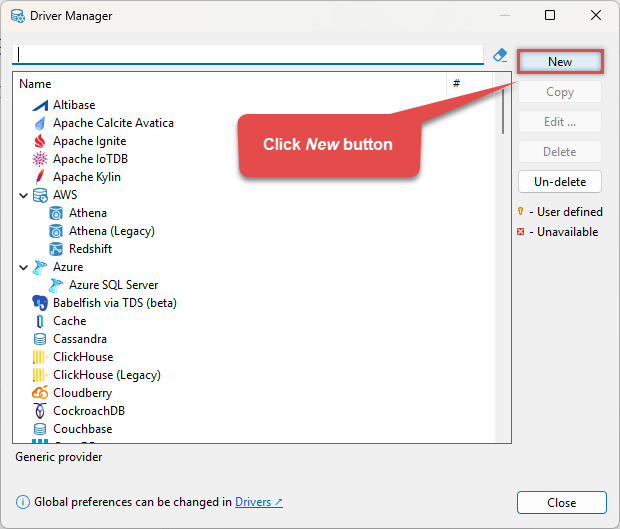
-
Configure the connection settings by entering the Driver Name and Class Name (
optional for Apache Spark):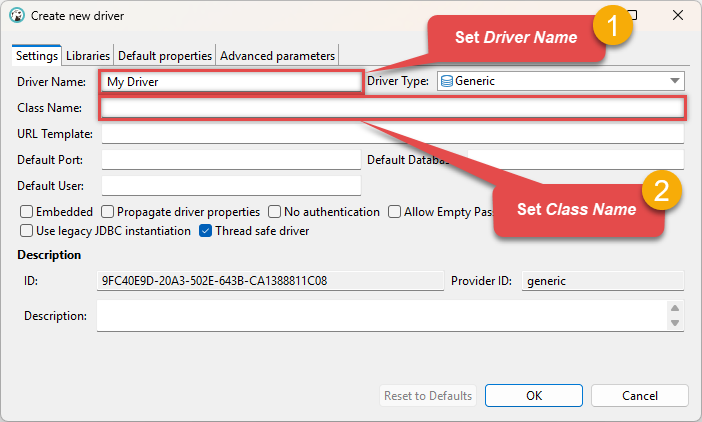 optional for Apache Spark
optional for Apache Spark -
Go to the Libraries tab, click Add File, and select your Apache Spark driver library file(s), e.g.
D:\Drivers\JDBC\hive-jdbc-standalone.jar: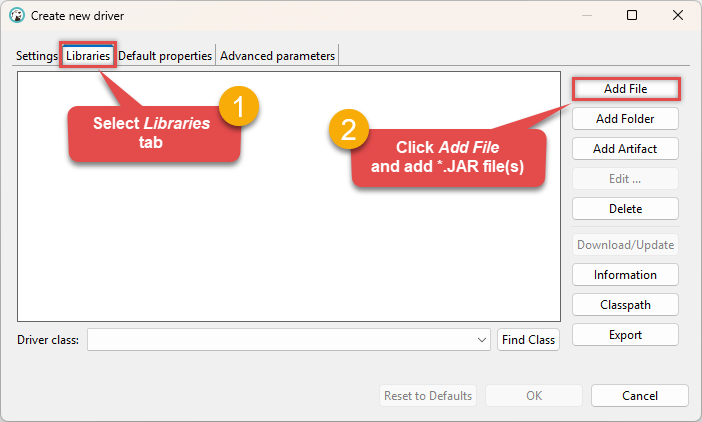 Make sure to add all the required library dependencies.
Make sure to add all the required library dependencies. -
Your JDBC driver
jarlibrary is now added: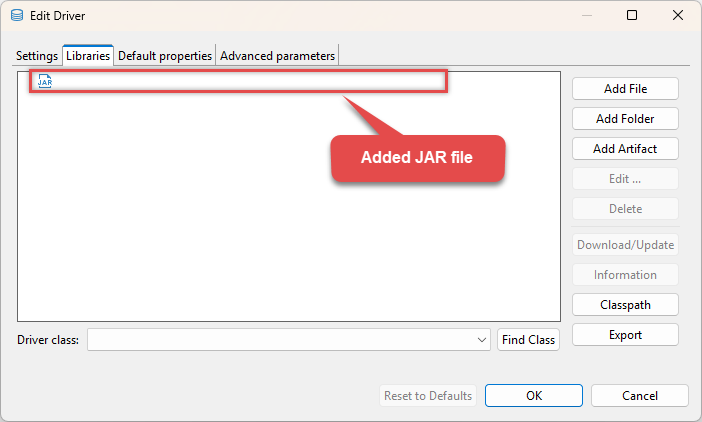 D:\Drivers\JDBC\hive-jdbc-standalone.jar
D:\Drivers\JDBC\hive-jdbc-standalone.jar -
(Optional). If required by your JDBC driver, add additional properties by going to the Default properties tab, Right-clicking on the background, and selecting Add new property:
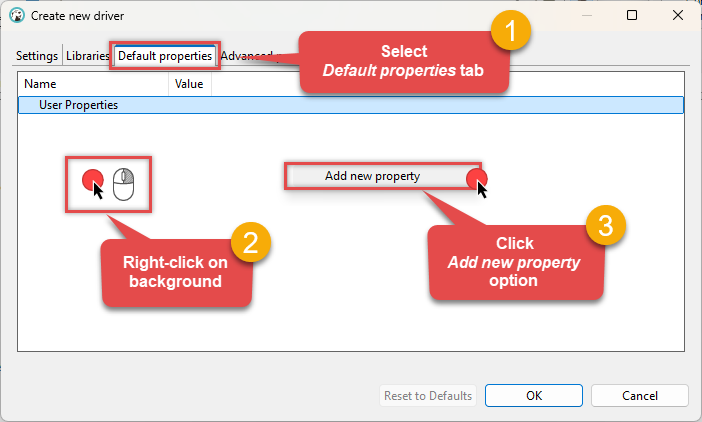
-
Click on a value to modify it, then click OK to finish:
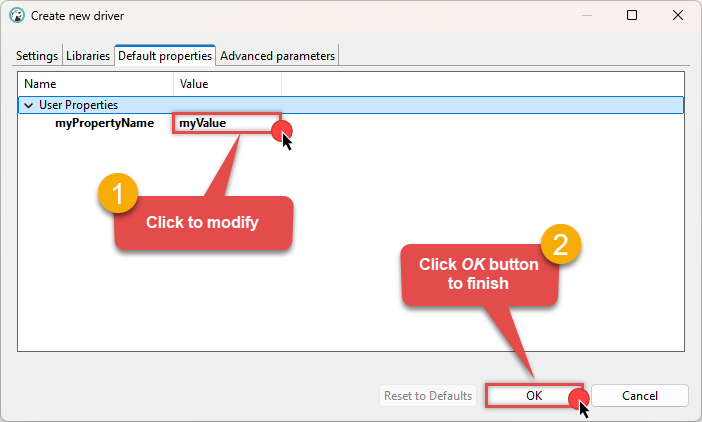
We are now ready to test the connection. Let's proceed!
Test connection
-
Click the New Database Connection icon in the toolbar:
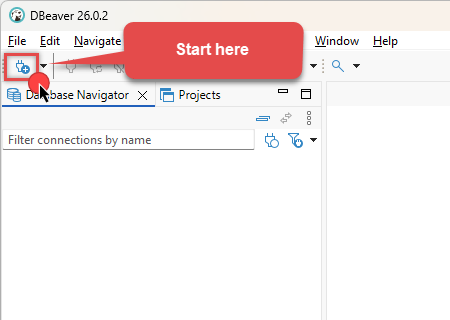
-
Select your newly created JDBC driver from the list and click Next:
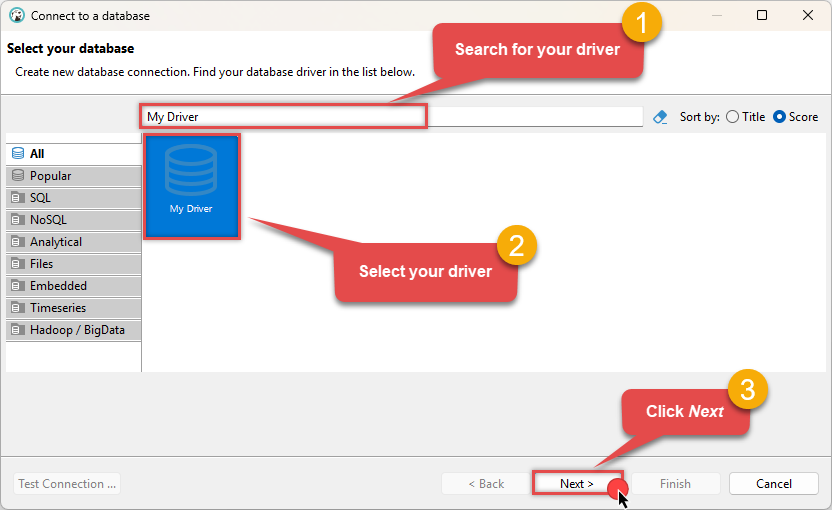
-
Enter your JDBC URL (e.g.
jdbc:hive2://spark-thrift-server-host:10000), click Test Connection to verify it works, and then click Finish: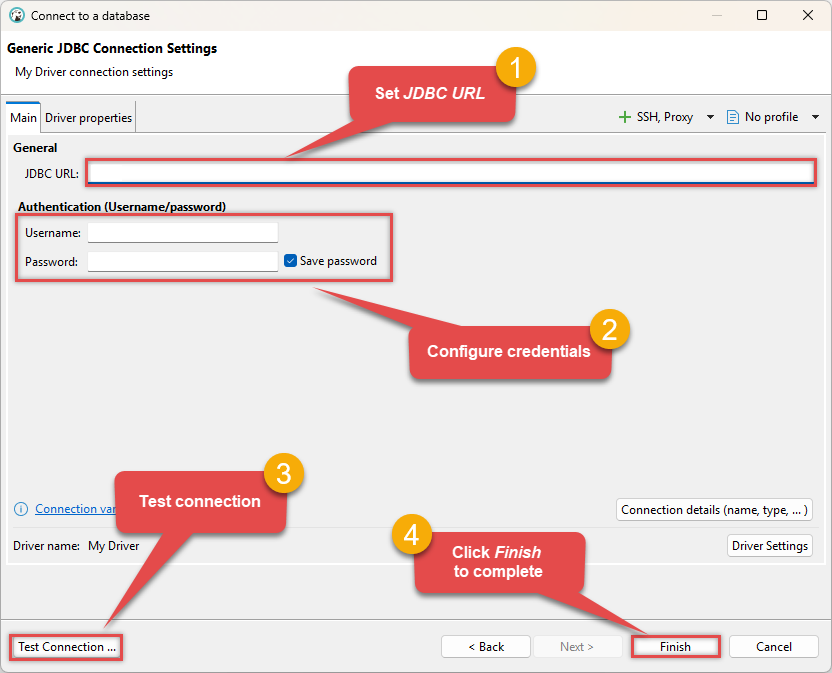 jdbc:hive2://spark-thrift-server-host:10000
jdbc:hive2://spark-thrift-server-host:10000 -
Finally, expand the database and table list to check the connection status:
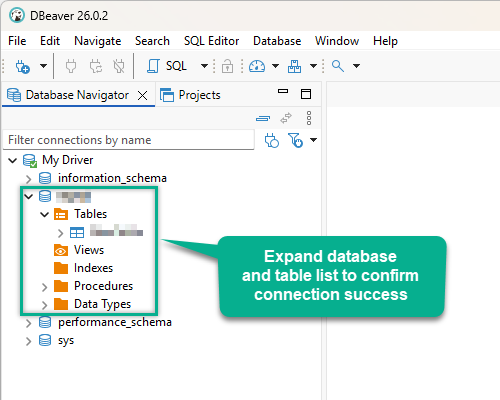
There are two possible outcomes from the connection test:
- Reason:The JDBC driver works perfectly, meaning the issue lies within your ODBC data source configuration.
- Action:Double-check your ODBC data source configuration and ensure it matches the settings that successfully connected in DBeaver.
-
Reason:There is likely an issue with the JDBC driver configuration or the connection details provided.
-
Action:Contact the ZappySys Support Team for assistance.
If you are still experiencing issues or need further help, please contact us:
Chat with an ExpertFrequent issues and solutions
Below are some useful community articles to help you troubleshoot and configure the ZappySys JDBC Bridge Driver:
-
How to combine multiple JAR files
Learn how to merge multiple
.jardependencies when your JDBC driver requires more than one file. -
How to fix JBR error: “Data lake is not available / Unable to verify trust for server certificate chain”
Resolve SSL or certificate validation issues encountered during JDBC connections.
-
System Exception: “Java is not installed or not accessible”
Fix Java path or environment issues that prevent the JDBC Bridge from launching Java.
-
JDBC Bridge Driver disconnect from Java host error
Troubleshoot unexpected disconnection problems between your client application and the Java process.
-
Error: Could not open jvm.cfg while using JDBC Bridge Driver
Resolve JVM configuration path errors during driver initialization.
-
How to enable JDBC Bridge Driver logging
Enable detailed driver logging for better visibility during troubleshooting.
-
How to pass JDBC connection parameters (not by URL)
Learn how to specify connection properties programmatically instead of embedding them in the JDBC URL.
-
How to fix JDBC Bridge error: “No connection could be made because the target machine actively refused it”
Troubleshoot firewall or local port binding issues preventing communication with the Java host.
-
How to use JDBC Bridge options (System Property for Java command line, e.g., classpath, proxy)
Configure custom Java options like classpath and proxy using JDBC Bridge system properties.
Conclusion
In this guide, we demonstrated how to connect to Apache Spark using Java and integrate your data — all without writing complex code. It's worth noting that ZappySys JDBC Bridge Driver allows you to connect not only to Apache Spark, but to any Java application that supports JDBC (just use a different JDBC driver and configure it appropriately).
Ready to get started? Download ODBC PowerPack now or ping us via chat if you still need help:

 Connector")
















 Connector")


 Connector")


























