
Amazon S3 ODBC Driver (for JSON Files)Amazon S3 ODBC Driver for JSON files can be used to read JSON Files stored in AWS S3 Buckets. Using this driver you can easily integrate AWS S3 data inside SQL Server (T-SQL) or your BI / ETL / Reporting Tools / Programming Languages. Write familiar SQL queries to read data without any coding effort. This driver supports latest security standards, and optimized for large data files. It also supports reading compressed files (e.g. GZip /Zip). This driver is using same high performance data processing engine which was originally developed for JSON Connector in SSIS PowerPack. ODBC PowerPack and SSIS PowerPack, both products share many UI elements and concepts. We wrote many articles to explain various features in one product but concepts are mostly same in both products so hope you can reuse steps explained in different articles even though screenshots /steps may be slightly different. Feature Summary
|
|
| Download Help File Buy | View All Drivers |
Featured Articles
|

Amazon S3 JSON ODBC Driver UI
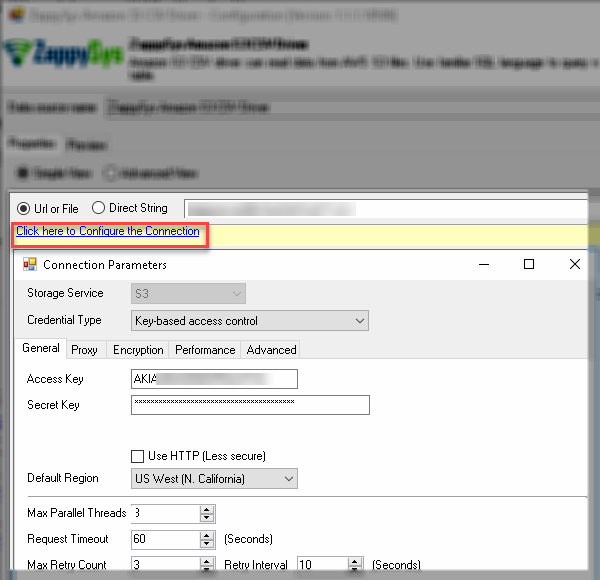
Configure Amazon S3 Connection – Amazon S3 ODBC Driver for JSON Files
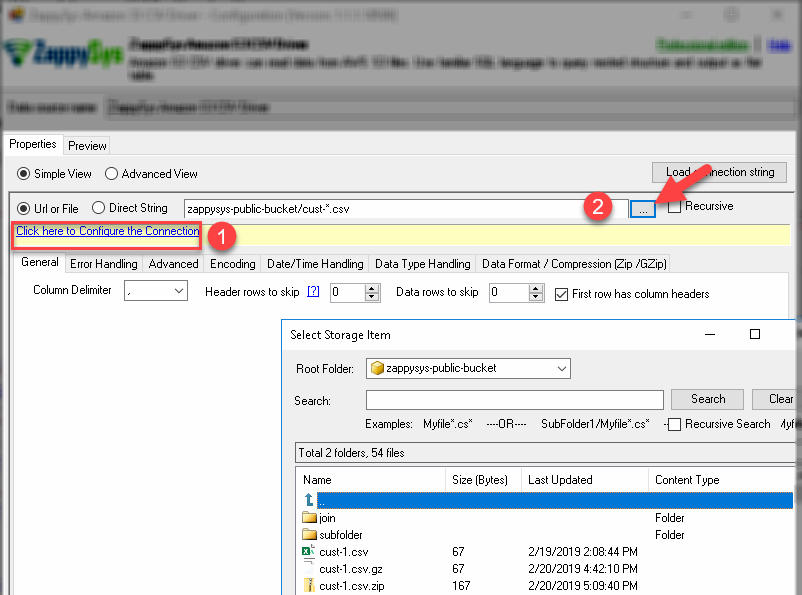
Browse File(s) – Amazon S3 File Selection
Integration Scenarios (Reporting / ETL / BI / Programming)
ZappySys ODBC Drivers built using ODBC standard which is widely adopted by industry for a long time. Which mean the majority of BI Tools / Database Engines / ETL Tools already there will support native / 3rd party ODBC Drivers. Below is the small list of most popular tools / programming languages our Drivers support. If your tool / programming language doesn’t appear in the below list, which means we have not documented use case but as long as your tool supports ODBC Standard, our drivers should work fine.

ZappySys Drivers for REST API, JSON, XML – Integrate with Power BI, Tableau, QlikView, QlikSense, Informatica PowerCenter, Talend, SQL Server, SSIS, SSAS, SSRS, Visual Studio / WinForm / WCF, Python, C#, JAVA, VB.net, PHP. PowerShell
|
BI / Reporting Tools |
|
ETL Tools |
|
|
Programming Languages |
|
ODBC Integration Screenshots in various tools
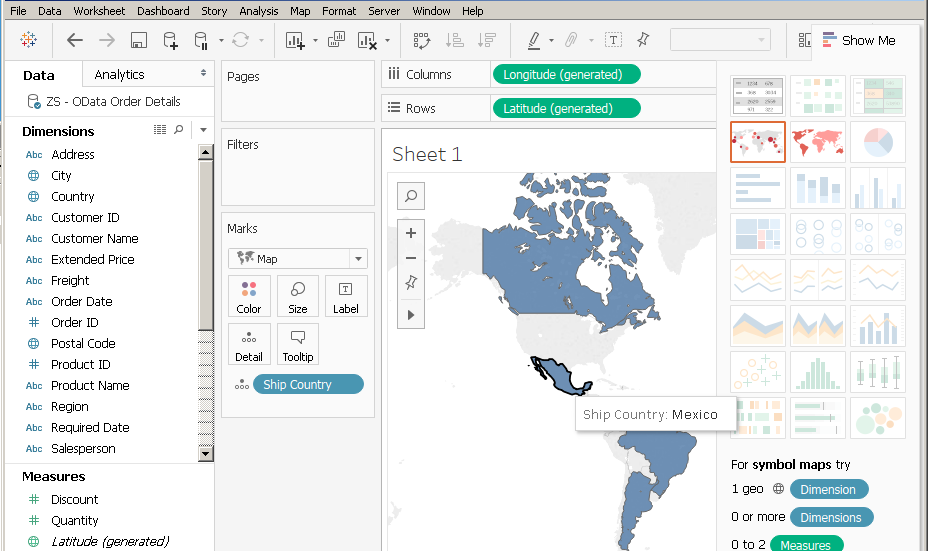 Tableau Integration - ODBC Driver connection for REST API / XML / JSON / SOAP / OData
Tableau Integration - ODBC Driver connection for REST API / XML / JSON / SOAP / OData

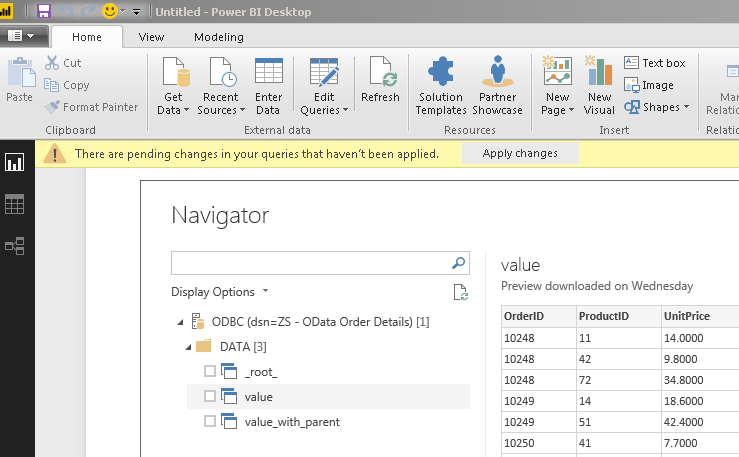
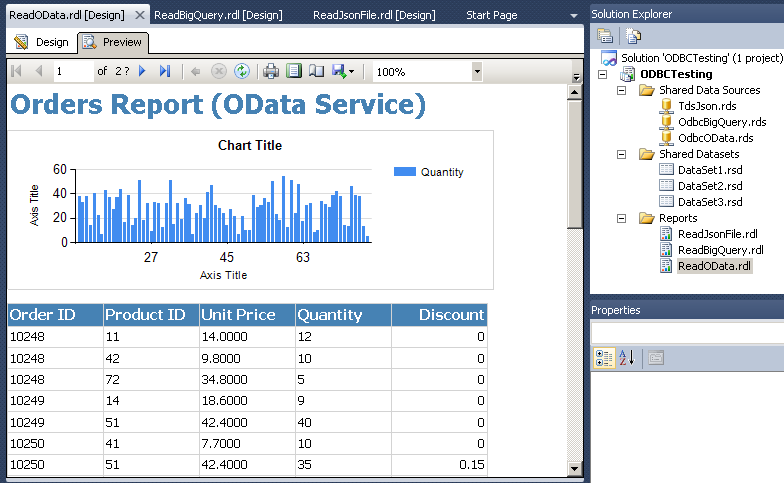
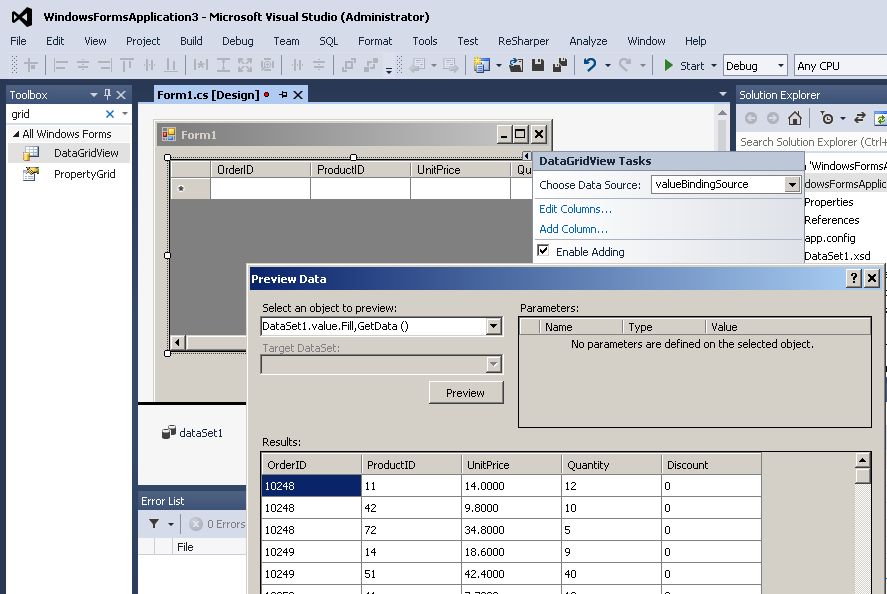
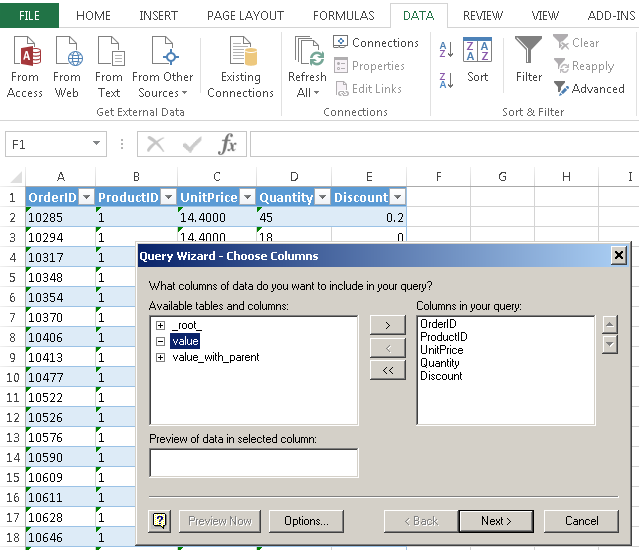
SQL Query Examples – Amazon S3 ODBC Driver for JSON Files
/*--------- Basic Read (API, File, Embedded) Query Single File ---------*/ SELECT * FROM $ WITH (SRC='zappysys-public-bucket/cust-1.json')
/*--------- Basic Read (API, File, Embedded) Query Multiple Files ---------*/ SELECT * FROM $ WITH ( SRC='zappysys-public-bucket/cust*-?.json' --,RECURSIVE='True' --Include files from sub folder )
/*--------- Basic Read (API, File, Embedded) Query direct JSON string (embedded inside query) ---------*/ SELECT * FROM rows WITH (DATA=' { rows : [ {id:1, name: "AAA"}, {id:2, name: "BBB"}, {id:3, name: "CCC"} ] }' )
/*--------- Functions String Manipulation ---------*/ SELECT substr('ZappySys', 1, 5) ,printf('%s %s %.2f', 'v1', CompanyName, CompanyId) ,('Str1' ||CompanyName || 'Str2' as ConcatExample , upper('ZappySys') , lower('ZappySys') , replace('ZappySys', 'Sys', 'XYZ') , instr( 'ZappySys', 'Sys') , trim ( ' Zappy Sys ') trim1 , trim ( '@@@ZappySys@@@', '@') trim2 , rtrim( ' ZappySys ') , ltrim( ' ZappySys ') , length ( CompanyName ) FROM $ WITH ( FILTER='$.Info.Rows[*]', DATA='{ Info: { Rows: [ { CompanyId: 1000 , CompanyName: "ZappySys" }, { CompanyId: 1001 , CompanyName: "Microsoft" } ] } }' )
/*--------- Functions Control flow ---------*/ SELECT COALESCE (10,20) coalesce1 --returns first non-null arg ,COALESCE(null, 20) coalesce2 --returns first non-null arg ,COALESCE(null, 20, 30, 40) coalesce3 --returns first non-null arg ,IFNULL(null,20) --returns first non-null arg. Same function as COALESCE but simple (just two arguments allowed) ,NULLIF (20,20) nullif1 --returns null if both argument same ,NULLIF (10,20) nullif2 --returns null if both argument same FROM $ WITH ( FILTER='$.Info.Rows[*]', DATA='{ Info: { Rows: [ { CompanyId: 1000 , CompanyName: "ZappySys" }, { CompanyId: 1001 , CompanyName: "Microsoft" } ] } }' )
/*--------- Functions Date/Time ---------*/ SELECT DATE('now') date_now ,STRFTIME('%Y-%m-%dT%H:%M:%f','now') formatted_Date_time ,DATETIME('now') datetime_now ,DATE('now','localtime') datetime_now_local ,TIME('now') time_now ,JULIANDAY('now') ,DATE('now', 'start of month', '+1 month' , '-1 day' ) dt_modify1 ,DATE('now', '+5 day') dt_modify2 FROM $ WITH (DATA='{ Info: { Rows: [ { CompanyId: 1000 , CompanyName: "ZappySys" }, { CompanyId: 1001 , CompanyName: "Microsoft" } ] } }' )
/*--------- Functions Math ---------*/ SELECT abs(-500) ,random()(1000.236, 2) ,round(1000.236, 2) FROM $ WITH (DATA='{ Info: { Rows: [ { CompanyId: 1000 , CompanyName: "ZappySys" }, { CompanyId: 1001 , CompanyName: "Microsoft" } ] } }' )
/*--------- Language Features Group By / Limit / Order By ---------*/ SELECT Country AS Invoice_Country ,SUM(UnitPrice * Quantity) AS Invoice_Total FROM $ WHERE Discount > 0 --AND OrderDate<=DATETIME('1997-12-31 00:00:00') -- OR use DATE('1997-12-31') DateTime column can be queried this way. You must wrap DATETIME function around it. Also must use 'yyyy-MM-dd' or 'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd HH:mm:ss.fff' format (where fff is milliseconds) GROUP BY Country HAVING SUM(UnitPrice * Quantity) > 1000 ORDER BY Invoice_Total DESC --,DATETIME(OrderDate) LIMIT 3 WITH (SRC='zappysys-public-bucket/invoices.json')
/*--------- Language Features Case Statement ---------*/ SELECT name , CASE id WHEN 1 THEN 1+1 WHEN 2 THEN 2+2 ELSE 0 END ThisIsCaseColumn FROM rows $ WITH (DATA=' { rows : [ {id:1, name: "AAA"}, {id:2, name: "BBB"}, {id:3, name: "CCC"} ] }' )
/*--------- Language Features UNION ALL / UNION Statement ---------*/ SELECT * into #tbl1 FROM $ WITH ( --enter path in SRC or use static value in DATA --SRC='zappysys-public-bucket/api/data.csv' --SRC='zappysys-public-bucket/some*.csv' --SRC='zappysys-public-bucket/somefile.csv' DATA='{ rows : [{id:1, name: "AAA"}, {id:2, name: "BBB"}]}' ); SELECT * into #tbl2 FROM rows $ WITH (DATA='{ rows : [{id:3, name: "CCC"}, {id:4, name: "DDD"}]}'); select * from #tbl1 UNION ALL select * from #tbl2;
/*--------- Language Features Pivot Value (Columns to Rows) ---------*/ SELECT Pivot_Name as ProjectName, Pivot_Value_id as Id, Pivot_Value_code as Code, Pivot_Value_budget as Budget FROM $ WITH( Filter='$.projects', --enter path in SRC or use static value in DATA' --SRC='zappysys-public-bucket/api/data.json' --SRC='zappysys-public-bucket/some*.json' --SRC='zappysys-public-bucket/somefile.json' DATA=' { projects : { P101 : {id:1, code: "AAA", budget:1500.10}, P102 : {id:2, code: "BBB", budget:7000.20}, P103 : {id:3, code: "CCC", budget:1100.10} } } ', EnablePivot='True' )
/*--------- Functions JSON ---------*/ select json_value(j1,"$.V1"), json_array_first(j2), json_array_last(j2), json_array_nth(j2,1) from array WITH (DATA= '{"array" : [{"c1": "abc", "c2": "ABC", "j1": "{''V1'':''value1''}", "j2": "[13,22,''31'']"}] }')
/*--------- Array Transformation Query Simple 2D Array ---------*/ SELECT * FROM rows WITH( --enter path in SRC or use static value in DATA' --SRC='zappysys-public-bucket/api/data.json' --SRC='zappysys-public-bucket/some*.json' --SRC='zappysys-public-bucket/somefile.json' DATA=' { "columns": ["RecordID","CustomerID","CustomerName"], "rows": [ [1,"AAA","Customer A"], [2,"BBB","Customer B"], [3,"CCC","Customer C"] ] }' ,ArrayTransformType='TransformSimpleTwoDimensionalArray' ,ArrayTransColumnNameFilter='$.columns[*]' )
ZappySys Data Gateway (ODBC Bridge for SQL Server / JAVA / Linux / Mac)
ZappySys has developed a unique bridge called ZappySys Data Gateway Service (ZSDG) which can help to access our Drivers in SQL Server or JAVA based Apps or Non-Windows OS (e.g. Mac, Linux). ZappySys Data Gateway service can run in the cloud (VM Exposed to internet) or you can install locally on-premises.
Client application can connect to Data Gateway Service using any Microsoft SQL Server compatible driver (i.e. SQL Server ODBC, OLEDB, ADO.net or JDBC Driver or Linked Server in SQL Server). Data Gateway can be installed on the central server where you can have many users who can connect to Data Gateway to use ZappySys Drivers without installing anything on their machine. Data Gateway Service understands TDS Protocol and Client App can be running on any machine or operating system (MacOS, Linux, Windows).
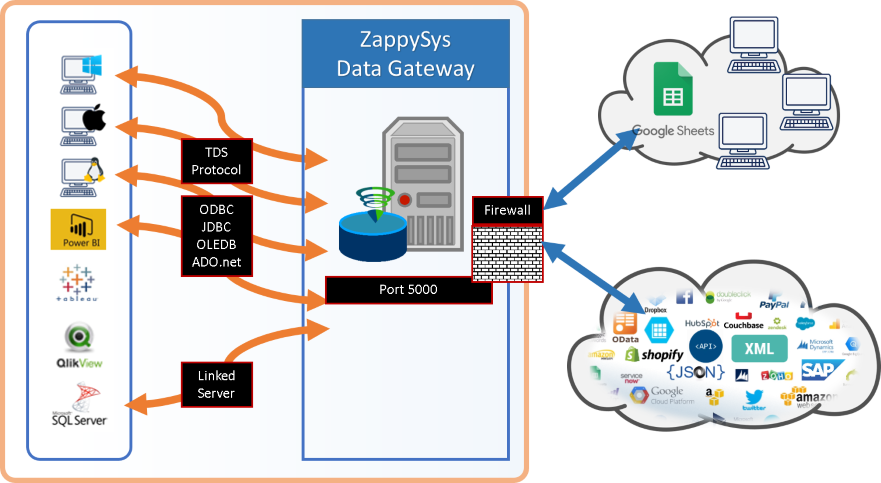
ZappySys Data Gateway – Connect to JSON, XML, OData, REST API, SOAP data sources using TDS protocol compatible drivers (or any SQL Server ODBC, JDBC, OLEDB, ADO.net driver )
Microsoft SQL Server Integration using Data Gateway Service (T-SQL)
Here is one possible use case of using Data Gateway Service. Any DBA or Non-Programmer can start writing T-SQL queries to use ZappySys Drivers (e.g. REST API, JSON, XML, CSV data source) right inside your usual T-SQL code (You can access data from Salesforce, REST API, JSON, XML, CSV inside Views, Functions or SQL Stored Procedures).
This approach can eliminate any possible ETL work needed to extract data outside of SQL Server, you can start using your existing SQL Skill to achieve previously hard to achieve scenarios without coding.
For many other possible use case of Data Gateway click here.
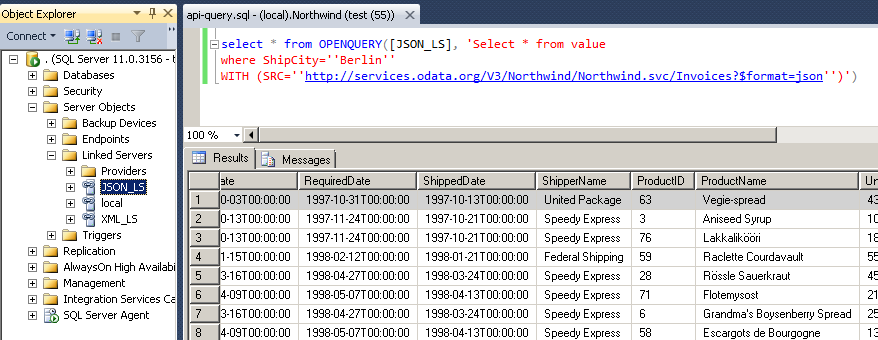
SQL Server Integration Example – Query REST API / JSON Files / XML Files inside SQL Server using ZappySys Data Gateway Service (Use of Linked Server / OPENQUERY Feature in T-SQL Code / SSMS)
Video Tutorial – Calling ZappySys Drivers inside SQL Server (JSON / REST Driver use case)
Here is a short video to demonstrate a use case of Data Gateway. With this approach you can import data from REST API or any other data source for which ZappySys offers Drivers (e.g. Amazon S3, Azure, SFTP, Salesforce, XML , CSV)
Programming Language Examples
Most programming languages come with out of the box support for ODBC. Which means you can use ZappySys ODBC drivers inside your favorite language. Here are few languages which already support ODBC. We have used JSON Driver / SQL query as an example but concept is same for other drivers too. Refer to help file to learn more about Driver specific Connection String and SQL Query.
using (OdbcConnection conn = new OdbcConnection("DRIVER ={ZappySys Amazon S3 JSON Driver};")) { conn.Open(); cmd = new OdbcCommand( @"SELECT Country as Invoice_Country, SUM(UnitPrice * Quantity) Total FROM value GROUP BY Country ORDERBY Total DESC", conn); var rdr = cmd.ExecuteReader(); while (rdr.Read()) { Console.WriteLine("---- Fetching Row -------"); for (i = 0; i < rdr.FieldCount; i++) { Console.Write("Field {0}={1} ", i, rdr[i]); } Console.WriteLine(""); } }
//Assuming the Microsoft SQL Server JDBC Driver is in below folder //C:\Program Files\Microsoft JDBC Driver 6.0 for SQL Server\sqljdbc_6.0\enu\auth\x64 private static final String jdbcDriver = "com.microsoft.sqlserver.jdbc.SQLServerDriver"; //The JDBC connection URL to connect to ZappySys Data Gateway Service using SQL Server driver private static final String jdbcURL = "jdbc:sqlserver://localhost:5000;databasename=master;user=tdsuser;password=tds123;"; //Connect to the database Connection databaseConnection = DriverManager.getConnection(jdbcURL); System.out.println("Connected to ZappySys Data Gateway Service using Microsoft SQL Server JDBC driver"); //declare the statement object Statement sqlStatement = databaseConnection.createStatement(); ResultSet rs = sqlStatement.executeQuery("SELECT Country , SUM(UnitPrice * Quantity) Total " + "FROM value " + "GROUP BY Country " + "WITH (SRC='https://services.odata.org/V3/Northwind/Northwind.svc/Invoices?$format=json')"); while (rs.next()) { System.out.println("-----Fetching new row----\n"); System.out.println(rs.getString("Country") + "\n"); //System.out.println(rs.getString("Total") + "\n"); }
#Example of using ODBC driver inside Python using pyodbc library (Read more info about pyodbc from below) #https://github.com/mkleehammer/pyodbc/wiki import pyodbc #connect to api service using ZappySys ODBC driver for JSON #Use DSN #conn = pyodbc.connect(r'DSN=MyZappyDsnName;') # OR Use direct connection string conn = pyodbc.connect( r'DRIVER={ZappySys Amazon S3 JSON Driver};' ) cursor = cnxn.cursor() #execute query to fetch data from API service cursor.execute("SELECT * FROM value ORDER BY Country WITH (SRC='https://services.odata.org/V3/Northwind/Northwind.svc/Invoices?$format=json')") row = cursor.fetchone() while row: print row[0] row = cursor.fetchone()
echo "Example of using ZappySys ODBC Driver in PHP\n"; $conn = odbc_connect("DRIVER={ZappySys Amazon S3 JSON Driver};", "", ""); $sql = "SELECT * FROM value ORDER BY Country WITH (SRC='https://services.odata.org/V3/Northwind/Northwind.svc/Invoices?$format=json')"; $rs = odbc_exec($conn,$sql); echo "Fetching first row....\n"; odbc_fetch_row($rs); echo "Country=" . odbc_result($rs,"Country") . "\n"; echo "Closing connection ....\n"; odbc_close($conn);
$conn = New-Object System.Data.Odbc.OdbcConnection $conn.ConnectionString = "DRIVER={ZappySys Amazon S3 JSON Driver}" #--OR-- Use DSN name #$conn.connectionstring = "DSN=MyDSNName" $conn.Open() # ------------------------------------------------------------------------------- # In powershell $ is special char so we used `$ in below string to escape it. # Also We used multi string start with "@<new line> and ends with <new line>"@ # ------------------------------------------------------------------------------- $sql = @" SELECT * FROM value WITH (SRC='https://services.odata.org/V3/Northwind/Northwind.svc/Customers?`$format=json') "@ $cmd = $conn.CreateCommand() $cmd.CommandText = $sql $dataset = New-Object System.Data.DataSet #Load data in DataSet (New-Object System.Data.Odbc.OdbcDataAdapter($cmd)).Fill($dataSet) #Export datatable to file in CSV format $dataset.Tables[0] | ConvertTo-csv -NoTypeInformation -Delimiter "`t" | Out-File "c:\temp\dump.csv" -fo Write-Host "Total rows $($dataSet.Tables[0].Rows.Count)" $conn.Close()