
Introduction
You can connect to your ElasticSearch data from SSAS via the high-performance ElasticSearch ODBC Driver. We'll walk you through the entire setup.
Let's not waste time and get started!
Create data source in ZappySys Data Gateway
In this section we will create a data source for ElasticSearch in the Data Gateway. Let's follow these steps to accomplish that:
-
Download and install ODBC PowerPack (if you haven't already).
-
Search for
gatewayin the Windows Start Menu and open ZappySys Data Gateway Configuration:
-
Go to the Users tab and follow these steps to add a Data Gateway user:
- Click the Add button
-
In the Login field enter a username, e.g.,
john - Then enter a Password
- Check the Is Administrator checkbox
- Click OK to save

-
Now we are ready to add a data source:
- Click the Add button
- Give the Data source a name (have it handy for later)
- Then select Native - ZappySys API Driver
- Finally, click OK
ElasticsearchDSNZappySys API Driver
-
When the Configuration window appears give your data source a name if you haven't done that already, then select "ElasticSearch" from the list of Popular Connectors. If "ElasticSearch" is not present in the list, then click "Search Online" and download it. Then set the path to the location where you downloaded it. Finally, click Continue >> to proceed with configuring the DSN:
ElasticsearchDSNElasticSearch
-
Select your authentication scenario below to expand connection configuration steps to:
- Configure the authentication in ElasticSearch.
- Enter those details into the ZappySys API Driver data source configuration.
Basic Authentication (UserId/Password)
ElasticSearch authentication
For Local / Hosted Instance by you
- Get your userid / password and enter on the connection UI
For Managed Instance (By Bonsai search)
If your instance is hosted by bonsai then perform these steps to get your credentials for API call- Go to https://app.bonsai.io/clusters/{your-instance-id}/tokens
- Copy Access Key and Access Secret and enter on the connection UI. Click Test connection.
- If your Cluster has no data you can generate sample data by visiting this URL and click Add Sample Data https://{your-cluster-id}.apps.bonsaisearch.net/app/home#/tutorial_directory
API Connection Manager configuration
Just perform these simple steps to finish authentication configuration:
-
Set Authentication Type to
Basic Authentication (UserId/Password) [Http] - Optional step. Modify API Base URL if needed (in most cases default will work).
- Fill in all the required parameters and set optional parameters if needed.
- Finally, hit OK button:
ElasticsearchDSNElasticSearchBasic Authentication (UserId/Password) [Http]http://localhost:9200Optional Parameters User Name (or Access Key) Password (or Access Secret) Ignore certificate related errors  Find full details in the ElasticSearch Connector authentication reference.
Find full details in the ElasticSearch Connector authentication reference.Windows Authentication (No Password)
ElasticSearch authentication
No instructions available.
API Connection Manager configuration
Just perform these simple steps to finish authentication configuration:
-
Set Authentication Type to
Windows Authentication (No Password) [Http] - Optional step. Modify API Base URL if needed (in most cases default will work).
- Fill in all the required parameters and set optional parameters if needed.
- Finally, hit OK button:
ElasticsearchDSNElasticSearchWindows Authentication (No Password) [Http]http://localhost:9200Optional Parameters Ignore certificate related errors
Find full details in the ElasticSearch Connector authentication reference. -
Once the data source connection has been configured, it's time to configure the SQL query. Select the Preview tab and then click Query Builder button to configure the SQL query:
 ZappySys API Driver - ElasticSearchRead and write Elasticsearch data effortlessly. Integrate, manage, and automate indexes and documents — almost no coding required.ElasticsearchDSN
ZappySys API Driver - ElasticSearchRead and write Elasticsearch data effortlessly. Integrate, manage, and automate indexes and documents — almost no coding required.ElasticsearchDSN
-
Start by selecting the Table or Endpoint you are interested in and then configure the parameters. This will generate a query that we will use in SSAS to retrieve data from ElasticSearch. Hit OK button to use this query in the next step.
SELECT * FROM Indexes Some parameters configured in this window will be passed to the ElasticSearch API, e.g. filtering parameters. It means that filtering will be done on the server side (instead of the client side), enabling you to get only the meaningful data
Some parameters configured in this window will be passed to the ElasticSearch API, e.g. filtering parameters. It means that filtering will be done on the server side (instead of the client side), enabling you to get only the meaningful datamuch faster . -
Now hit Preview Data button to preview the data using the generated SQL query. If you are satisfied with the result, use this query in SSAS:
ZappySys API Driver - ElasticSearchRead and write Elasticsearch data effortlessly. Integrate, manage, and automate indexes and documents — almost no coding required.ElasticsearchDSNSELECT * FROM Indexes You can also access data quickly from the tables dropdown by selecting <Select table>.A
You can also access data quickly from the tables dropdown by selecting <Select table>.AWHEREclause,LIMITkeyword will be performed on the client side, meaning that thewhole result set will be retrieved from the ElasticSearch API first, and only then the filtering will be applied to the data. If possible, it is recommended to use parameters in Query Builder to filter the data on the server side (in ElasticSearch servers). -
Click OK to finish creating the data source.
-
Once done, go to the Network Settings tab and Add a firewall rule for inbound traffic:
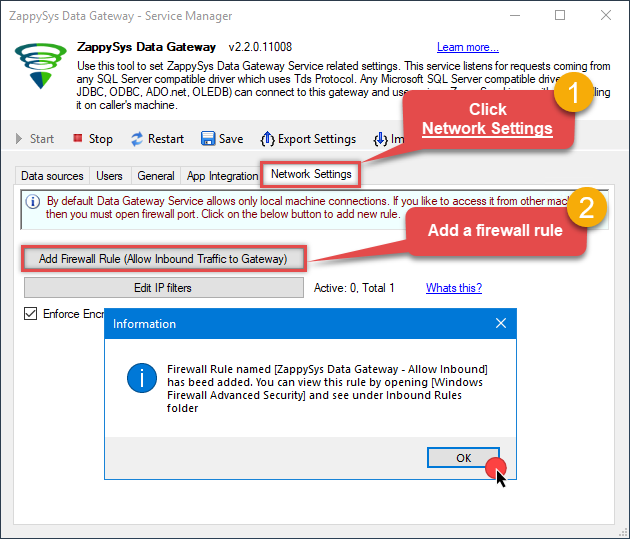
- This will initially allow all inbound traffic.
- Click Edit IP filters to restrict access to specific IP addresses or ranges.
-
Crucial Step: After creating or modifying the data source, you must:
- Click the Save button to persist your changes.
- Hit Yes when prompted to restart the Data Gateway service.
This ensures all changes are properly applied:
 Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Skipping this step may cause the new settings to fail, preventing you from connecting to the data source.
Read ElasticSearch data in SSAS cube
With the data source created in the Data Gateway (previous step), we're now ready to read ElasticSearch data in an SSAS cube. Before we dive in, open Visual Studio and create a new Analysis Services project. Then, you're all set!
Create data source based on ZappySys Data Gateway
Let's start by creating a data source for a cube, based on the Data Gateway's data source we created earlier. So, what are we waiting for? Let's do it!
-
Create a new data source:

-
Once a window opens,
select Create a data source based on an existing or new connection option and
click New...:

-
Here things become a little complicated, but do not despair, it's only for a little while.
Just perform these little steps:
- Select Native OLE DB\SQL Server Native Client 11.0 as provider.
- Enter your Server name (or IP address) and Port, separated by a comma.
- Select SQL Server Authentication option for authentication.
- Input User name which has admin permissions in the ZappySys Data Gateway.
- In Database name field enter the same data source name you use in the ZappySys Data Gateway.
- Hopefully, our hard work is done, when we Test Connection.
ElasticsearchDSNElasticsearchDSN If SQL Server Native Client 11.0 is not listed as Native OLE DB provider, try using these:
If SQL Server Native Client 11.0 is not listed as Native OLE DB provider, try using these:- Microsoft OLE DB Driver for SQL Server
- Microsoft OLE DB Provider for SQL Server
-
Indeed, life is easy again:

Add data source view
We have data source in place, it's now time to add a data source view. Let's not waste a single second and get on to it!
-
Start by right-clicking on Data Source Views and then choosing New Data Source View...:

-
Select the previously created data source and click Next:

-
Ignore the Name Matching window and click Next.
-
Add the tables you will use in your SSAS cube:
 For cube dimensions, consider creating a Virtual Table in the Data Gateway's data source. Use the
For cube dimensions, consider creating a Virtual Table in the Data Gateway's data source. Use theDISTINCTkeyword in theSELECTstatement to get unique values from the facts table, like this:SELECT DISTINCT Country FROM CustomersFor demonstration purposes we are using sample tables which may not be available in ElasticSearch. -
Review your data source view and click Finish:

-
Add the missing table relationships and you're done!

Create cube
We have a data source view ready to be used by our cube. Let's create one!
-
Start by right-clicking on Cubes and selecting New Cube... menu item:

-
Select tables you will use for the measures:

-
And then select the measures themselves:

-
Don't stop and select the dimensions too:

-
Move along and click Finish before the final steps:

-
Review your cube before processing it:

-
It's time for the grand finale! Hit Process... to create the cube:

-
A splendid success!

Execute MDX query
The cube is created and processed. It's time to reap what we sow! Just execute an MDX query and get ElasticSearch data in your SSAS cube:

ElasticSearch Connector actions
Got a specific use case in mind? We've mapped out exactly how to perform a variety of essential ElasticSearch operations directly in SSAS, so you don't have to figure out the setup from scratch. Check out the step-by-step guides below:
- Create Index
- Delete Index
- List indexes
- List aliases
- Get Index or Alias metadata
- Get documents from Index or Alias
- Get document by ID from Index or Alias
- Search / Query documents
- Count documents
- Insert documents
- Upsert documents
- Update documents
- Delete documents
- Make Generic REST API Request
- Make Generic REST API Request (Bulk Write)
Conclusion
In this guide, we demonstrated how to connect to ElasticSearch in SSAS and integrate your data — all without writing complex code.
Ready to get started? Download ODBC PowerPack now or ping us via chat if you still need help:


 Connector")







 Connector")












 Connector")





 Connector")





























