Home Page › Forums › FAQs – SSIS Tips and Tricks › Amazon Redshift Data Load restartability and best practices
Tagged: best practices, bulk load, compression, export csv, gzip, ibm netezza, redshift, redshift copy, restartability, s3, sql server, ssis
- This topic has 0 replies, 1 voice, and was last updated 8 years, 11 months ago by
ZappySys.
-
AuthorPosts
-
March 24, 2017 at 7:07 am #2166
ZappySys
KeymasterIntroduction
In this post you will learn how to load large dataset into Amazon Redshift using SSIS Amazon Redshift Data Transfer Task. For detailed article of Loading data into Redshift check this link
Loading large amount of data into Amazon Redshift with Restartability
When you loading data from Relational Source (i.e. ibm netezza or SQL Server) to Redshift using
Redshift Data Transfer Task then following major tasks performed.- Exporting Relational Data into CSV files (Export, Split and Compress)
- Uploading files to S3 bucket
- Loading S3 files into Amazon Redshift using COPY command (Parallel load of compressed files)
Out of those 3 steps most likely Step#1 will take longest time in many cases. If you want better restartability of long running JOBS which may fail after Step #1 then we recommend two step approach.
- Use SSIS Export CSV File Task for Step#1 (Export, Split, Compress). Check this article .
- Use SSIS Amazon Redshift Data Transfer Task for Step#2 and Step#3 (Upload to S3, Load to Redshift, Archive S3 files, Summary/Error Reporting) – Use Bulk load from Files to Redshift option on user interface
- User SSIS Advanced File System Task to archive or delete local files
Below steps shows how to use Export CSV File Task for Export, Split and Compress
Step-1: Export SQL Server Data as CSV file
To extract data from SQL Server you can use Export CSV Task. It has many options which makes it possible to split large amount of data into multiple files. You can specify single table or multiple tables as your data source.
For multiple table use vertical bar. e.g. dbo.Customers|dbo.Products|dbo.Orders. When you export this it will create 3 files ( dbo.Customers.csv , dbo.Products.csv, dbo.Orders.csv )
Steps:
- Drag ZS Export CSV Task from Toolbox
- Double click task to configure
- From connection drop down select New connection option (OLEDB or ADO.net)
- Once connection is configured for Source database specify SQL Query to extract data as below
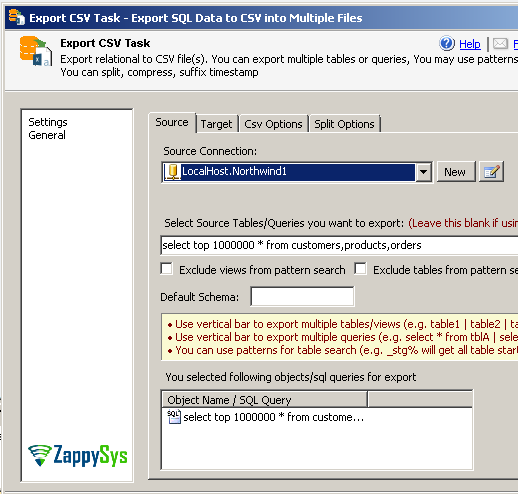
- Now go to target tab. Here you can specify full path for file. e.g. c:\ssis\temp\s3dump\cust.csv
Step-2: Compress CSV Files in SSIS ( GZIP format – *.gz )
Above steps will export file as CSV format without splitting or compression. But to compress file once exported you can go to Target tab of Export CSV Task and check [Compress file to *.gz format] option.
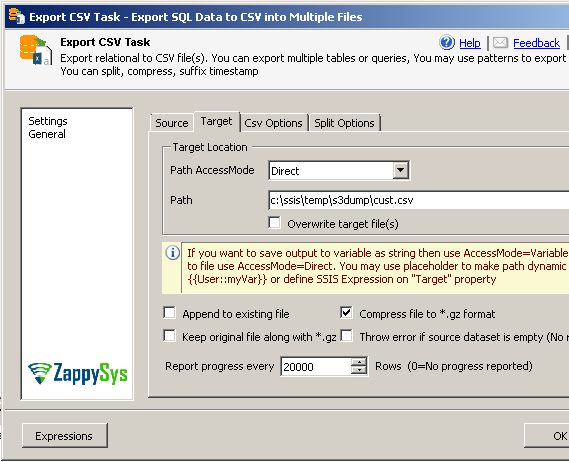
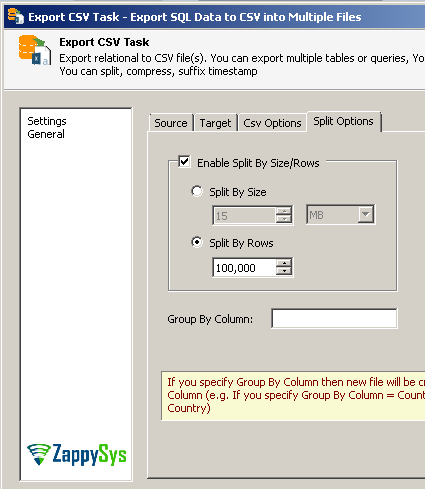
Step-3: Split CSV files by row count or data size in SSIS
Now lets look at how to split exported CSV files into multiple files so we can upload many files in parallel. Goto Split Options and check [Enable Split by Size/Rows]
Best Practices for Amazon Redshift data load in SSIS
Here are few best practices when using SSIS Amazon Redshift Data Transfer Task for Redshift Data Load
- Split large dataset into multiple files so files are between less than 1 GB after compression (More information)
- Avoid too many tasks in parallel inf you uploading data to multiple tables. Many network connection increases chance of timeout.
- If your load process is taking very long from start to finish then try to split file export in a separate task using Export CSV File task (as explained in the previous section).
- Adjust parallel threads on Redshift Connection manager and Redshift Data Transfer Task (Advanced Tabs) to fine tune as per your need (default setting is good most of the time but perform tests to get benchmark on different settings).
- Whenever possible use compression option to upload files in compressed format (gzip).
-
AuthorPosts
- The forum ‘FAQs – SSIS Tips and Tricks’ is closed to new topics and replies.