| Property Name |
Description |
| LoggingMode |
LoggingMode determines how much information is logged during Package Execution. Set Logging mode to Debugging for maximum log.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| Normal [0] |
Normal |
| Medium [1] |
Medium |
| Detailed [2] |
Detailed |
| Debugging [3] |
Debugging |
|
| PrefixTimestamp |
When you enable this property it will prefix timestamp before Log messages. |
| TreatBlankNumberAsNull |
Treat empty string as NULL for any numeric data types |
| TreatBlankBoolAsNull |
Treat empty string as NULL for bool data types |
| TreatBlankDateAsNull |
Treat empty string as NULL for any date/time data types |
| Encoding |
Encoding of source file
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| Default [0] |
Default |
| ASCII [1] |
ASCII |
| UTF8 [2] |
UTF-8 |
| UTF16 [3] |
UTF-16 LE (i.e. Unicode Little Endian) |
| UTF32 [4] |
UTF-32 |
| UTF8WithoutBOM [5] |
UTF-8 Without BOM |
| UTF32WithoutBOM [6] |
UTF-32 Without BOM |
| UTF7 [7] |
UTF-7 |
| UTF7WithoutBOM [8] |
UTF-7 Without BOM |
| UTF16WithoutBOM [9] |
UTF-16 Without BOM |
| BigEndian [10] |
UTF-16 BE (i.e. Unicode Big Endian) |
| BigEndianWithoutBOM [11] |
UTF-16 BE Without BOM |
|
| CharacterSet |
Character set for text (e.g. windows-1250 ) |
| Culture |
Culture code (e.g. pt-BT). This helps to parse culture specific number formats (e.g. In some culture you may have comma rather than decimal points 0.1 can be 0,1) |
| MaxRows |
Maximum XML records to fetch. Set this value to 0 for all records |
| EnableCustomReplace |
Enables custom search / replace in the document text after its read from the file/url or direct string. This replace operation happens before its parsed. This option can be useful for custom escape sequence in source document which is causing issue in the parser. You can replace such unwanted characters fore parser starts parsing the text. |
| SearchFor |
String you like to search for (Only valid when EnableCustomReplace option is turned on). If you want to enable Regular Expression pattern search then add --regex or --regex-ic (for case-insensitive search) at the end of your search string (e.g. ORDER-\d+--regex OR ORDER-\d+--regex-ic (case-insensitive search) ) |
| ReplaceWith |
String you like to replace with (Only valid when EnableCustomReplace option is turned on). If you added --regex or --regex-ic at the end of your SearchFor string then ReplaceWith can use numbered group placeholders (e.g. $1, $2...) or use group name as placeholder (e.g. ${username}, ${domain}) any where in the replacement string.
For example to search and replace emails and remove just user name from it you can do below
SearchFor=(?<username>\w+)(?<domain>@\w+.com)
ReplaceWith = ****$2
-OR-
ReplaceWith = ****${domain}
|
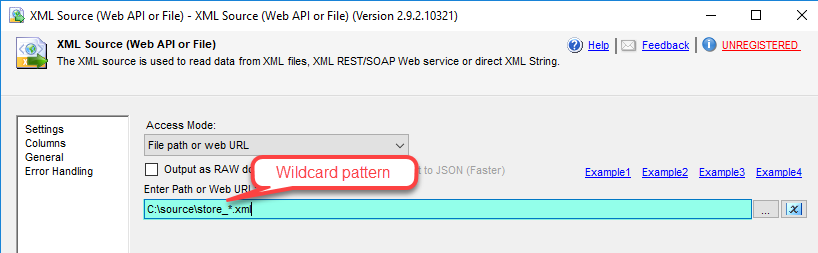
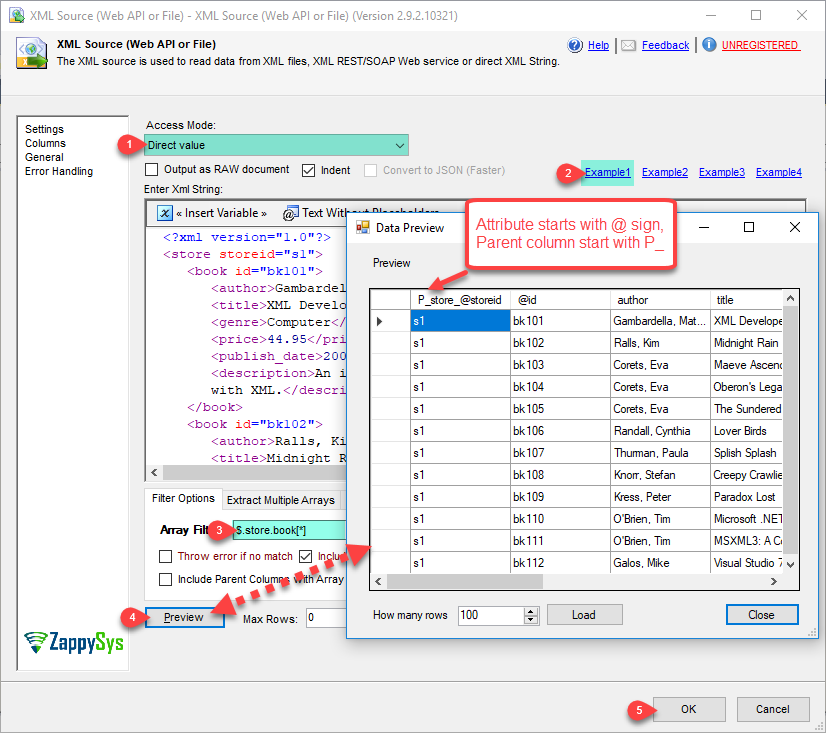
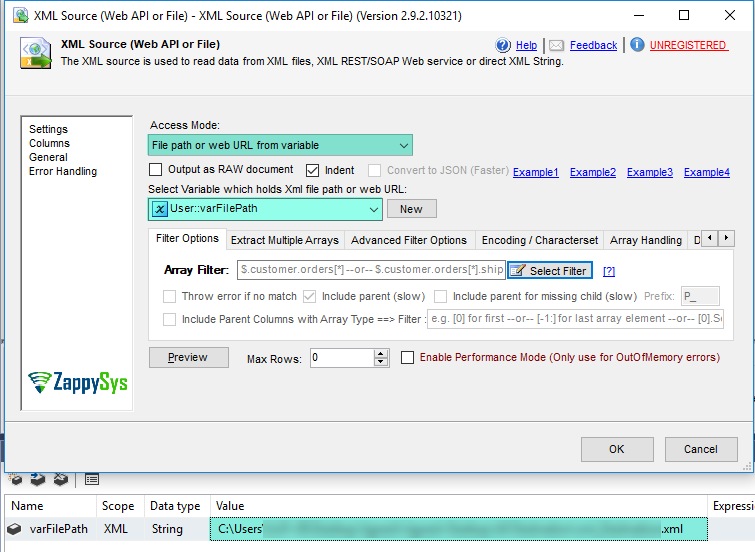
| AccessMode |
Defines how to read the XML file or direct string
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| DirectValue [0] |
Direct value |
| ValueFromVariable [1] |
Direct value from variable |
| DirectPath [2] |
File path or web URL |
| PathFromVariable [3] |
File path or web URL from variable |
|
| DirectValue |
Defines how to read the XML file or direct string or command line output. If you like to read from command line then simply prefix any valid command line with cmd:>. Here is more information about streaming data from command line output. Syntax: cmd:>[exe / bat folder]<exe-name> [arguments]
First argument is exe name or full path for exe or bat file. Second part is arguments for command line program. You can use double quotes around exe / batch file path if it contains space.
For *.bat or *.cmd file make sure to add [ @echo off ] in the first line (without brackets) else command itself is added in output. To read more please see product help file
For CSV Reader Set [Ignore Blank Lines] option to True
====================
Examples:
====================
cmd:>cmd /c dir *.dll /b
cmd:>aws iam list-users --output xml
cmd:>az vm list --output xml
cmd:>py c:\scripts\run-python.py
cmd:>powershell -executionpolicy bypass -File "c:\scrips\run.ps1"
cmd:>powershell -executionpolicy bypass -Command "[System.IO.StreamReader]::new((Invoke-WebRequest -URI https://zappysys.com/downloads/files/test/invoices.xml).RawContentStream).ReadToEnd()"
cmd:>c:\folder\my-batch-file.bat
cmd:>c:\folder\my-batch-file.bat option1 option2
cmd:>curl -k https://httpbingo.org/get
cmd:>curl.exe -k https://httpbingo.org/get
cmd:>c:\folder\curl.exe -k https://httpbingo.org/get
cmd:>"c:\folder with space\curl.exe" -k https://httpbingo.org/get
#Multi-Step Example in PowerShell (First command generate file, Second command display file content)
cmd:>powershell -executionpolicy bypass -Command "echo {{id:1}}{{id:2}} | Out-File c:\temp\dump.xml ; more c:\temp\dump.xml"
|
| ValueVariable |
Variable name which holds XML string |
| PathVariable |
Variable name which holds data file path or url |
| DirectPath |
XML file path (e.g. c:\data\myfile.xml) or pattern to process multiple files (e.g. c:\data\*.xml) |
| Recursive |
Include files from sub folders too. |
| EnableMultiPathMode |
Enable this option to treat DirectPath as list of paths / urls (separated by new line or double colon :: ). This option is very useful if you have many URLs / Paths with similar data structure and you want to return response from all URLs in one step (UNION all URLs with single dataset). Examples: http://someurl1::http://someurl2 --OR-- c:\file1::c:\file2 --OR-- c:\file1::https://someurl |
| ContinueOnFileNotFoundError |
By default process stops with error if specified local file is not found. Set this property to true if you wish to continue rather than throwing file not found error. |
| HttpHeaders |
Set this if you want to set custom Http headers. You may use variable anywhere in the header value using syntax {{User::YourVarName}}. Syntax of Header key value pair is : <request><header><name>x-myheader-1</name><value>AAA</value></header> <header><name>x-myheader-2</name><value>BBB</value></header></request> |
| HttpRequestData |
User defined data you wish to send along with your HTTP Request (e.g. Upload file data, Form POST data). Usually you have to set content-type of your data but if you select RequestMethod=POST then system will automatically set content-type=application/x-www-form-urlencoded. |
| HttpRequestMethod |
Http Web Request Method (e.g. POST, GET, PUT, LIST, DELETE...). Refer your API documentation if you are not sure which method you have to use. |
| HttpRequestContentType |
Specifies content type for data you wish to POST. If you select Default option then system default content type will be used (i.e. application/x-www-form-urlencoded). If you specify Content-Type header along with this option then header value takes precedence.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| Default [0] |
Default |
| TextPlain [1] |
Text (text/plain) |
| ApplicationJson [2] |
JSON (application/json) |
| ApplicationXml [3] |
XML (application/xml) |
| TextXml [4] |
XML (text/xml) |
| TextXmlUtf8 [5] |
XML (text/xml;charset=UTF-8) |
| TextHtml [6] |
HTML (text/html) |
| ApplicationFormUrlencoded [7] |
Form (application/x-www-form-urlencoded) |
| ApplicationOctetStream [8] |
Binary (application/octet-stream) |
| Raw [9] |
Raw (No content-type) |
| MultiPartMixed [10] |
Multipart Mixed (multipart/mixed) |
| ApplicationGraphql [11] |
GraphQL (application/graphql) |
|
| IsMultiPartUpload |
Set this option if you want to upload file(s) using either raw file data (i.e., POST raw file data) or send data using the multi-part encoding method (i.e. Content-Type: multipart/form-data).
A multi-part request allows you to mix key/value pairs and upload files in the same request. On the other hand, raw upload allows only a single file to be uploaded (without any key/value data).
==== Raw Upload (Content-Type: application/octet-stream) =====
To upload a single file in raw mode, check this option and specify the full file path starting with the @ sign in the Body (e.g. @c:\data\myfile.zip)
==== Form-Data / Multipart Upload (Content-Type: multipart/form-data) =====
To treat your request data as multi-part fields, you must specify key/value pairs separated by new lines in the RequestData field (i.e., Body). Each key/value pair should be entered on a new line, and key/value are separated using an equal sign (=). Leading and trailing spaces are ignored, and blank lines are also ignored.
If a field value contains any special character(s), use escape sequences (e.g., for NewLine: \r\n, for Tab: \t, for at (@): @). When the value of any field starts with the at sign (@), it is automatically treated as a file you want to upload. By default, the file content type is determined based on the file extension; however, you can supply a content type manually for any field using this format: [YourFileFieldName.Content-Type=some-content-type].
By default, file upload fields always include Content-Type in the request (non-file fields do not have Content-Type by default unless you supply it manually). If, for some reason, you don't want to use the Content-Type header in your request, then supply a blank Content-Type to exclude this header altogether (e.g., SomeFieldName.Content-Type=).
In the example below, we have supplied Content-Type for file2 and SomeField1. All other fields are using the default content type.
See the example below of uploading multiple files along with additional fields. If some API requires you to pass Content-Type: multipart/form-data rather than multipart/form-data, then manually set Request Header => Content-Type: multipart/mixed (it must start with multipart/ or it will be ignored).
file1=@c:\data\Myfile1.txt
file2=@c:\data\Myfile2.xml
file2.Content-Type=application/xml
SomeField1=aaaaaaa
SomeField1.Content-Type=text/plain
SomeField2=12345
SomeFieldWithNewLineAndTab=This is line1\r\nThis is line2\r\nThis is \ttab \ttab \ttab
SomeFieldStartingWithAtSign=\@MyTwitterHandle
|
| AllowAuthRedirectToAnyDomain |
By default when redirect happens (i.e. HTTP Code 301, 302, 307 and 308) to a different Host (domain or IP) then it removes the authorization header before redirecting to a new Host. If you trust the new host and you like to pass credentials after redirect then set this option. Without setting this option your HTTP request might fail. |
| JsonFormat |
Data format coming from HTTP Response. This is useful for example when you have OData service and you want to automatically consume all pages of data using odata.netUrl. Setting JsonFormat=Odata will automatically do it for you. This setting is only applicable if XML is coming from HTTP WebRequest.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| Notset [0] |
Notset |
| Json [1] |
JSON |
| Odata [2] |
OData (v3,v4) |
|
| UseProxy |
Enable custom proxy settings (If this is not set then system default proxy will be used. To disable proxy totally uncheck this option and check DoNotUseDefaultProxy option if available) |
| ProxyUrl |
Web URL of Proxy server (including port if necessary). [e.g. http://myproxyserver:8080/] |
| UseProxyCreds |
Enable passing userid and password to proxy server |
| ProxyUserName |
Proxy username |
| ProxyPassword |
Proxy password |
| NextUrlAttribute |
If Service response support pagination using some sort of next url attribute then specify which attribute name in XML Response string which holds next url. If no attribute found or its null then component will stop fetching next resultset. Example: $.pagingInfo.nextUrl |
| PrevUrlAttribute |
If Service response support pagination using some sort of prev/next url attribute then specify which previous link attribute name from XML Response string which holds previous url. |
| NextUrlStopIndicator |
Specifies value for NextUrlAttribute or StopIndicatorAttribute which indicates last page to stop pagination. If you have specified StopIndicatorAttribute then you can use Regular expression rather than static value to indicate last page. To use regular expression value of this property must start with regex= prefix. Example : regex=FALSE|N or use regex= to detect blank value or missing value (assuming you set StopIndicatorAttribute to something like $.hasMore) |
| StopIndicatorAttribute |
Attribute name or expression for attribute which can be used as stop indicator (e.g. $.hasMore --OR-- $.pagination.hasMore --OR-- $.data[0].hasMore). If this value is blank then NextUrlAttribute is used |
| NextUrlSuffix |
If you want to include certain text (or parameters) at the end of Next url then specify this attribute (e.g. &format=xml). Another common use case of this property is to supply pagination token to next Page URL. You can also use <%nextlink%> or <%nextlink_encoded%> placeholder (e.g. &cursor=<%nextlink_encoded%> ) |
| NextUrlWait |
This property indicates total number of milliseconds you want to wait before sending next request. This option allows you to adjust how many API calls can be made within certain timeframe. If your API Service has no limit then set this option to zero |
| ContinueOnUrlNotFoundError |
If this option is true then component will continue without exception on 404 error (Url not found). This allows you to consume data gracefully. |
| ContineOnAnyError |
Continue when any type of exception occurs during http request |
| ContineOnErrorForMessage |
Continue on error when specified substring found in response |
| ContineOnErrorForStatusCode |
Continue on error when specified status code returned from web server |
| ConsumeResponseOnError |
When error occurs no data is returned. Use this option to get content eventhough error occurs. When this option is checked you can't use [continue on error when specific string found in response] option |
| ErrorStatusCodeToMatch |
Status code to match when error occurs and ContineOnErrorForStatusCode option is true. If Response status code matches to this code then task continues to run |
| ErrorStatusCodeToMatchRegex |
Status code(s) to match - separated by vertical bar (e.g. 404|405). When error occurs and ContineOnErrorForStatusCode option is true then if StatusCode matches to this code(s) then task continues to run |
| ErrorSubstringToMatch |
Error substring to match when error occurs and ContineOnErrorForMessage option is true. If Response status code matches to this code then task continues to run |
| CookieContainerVariable |
Cookie Container can be used to maintain state between multiple web requests. Example: You can login to site like wordpress and then extract any private page content by simply passing authentication cookies using this variable. |
| RequestTimeout |
Http request Timeout in seconds. Set this to 0 if you want to use system default value (i.e. 100 seconds) |
| SecurityProtocol |
Specifies which security protocol is supported for HTTPS communication. Using this option you can enable legacy protocol or enforce to use latest version of security protocol (Note: TLS 1.2 is only supported in SSIS 2014 or Higher).
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| Default [0] |
System Default |
| Ssl3 [1] |
SSL v3.0 |
| Ssl3Plus [2] |
SSL v3.0 or higher |
| Tls [3] |
TLS v1.0 |
| TlsPlus [4] |
TLS v1.0 or higher |
| Tls11 [5] |
TLS v1.1 |
| Tls11Plus [6] |
TLS v1.1 or higher |
| Tls12 [7] |
TLS v1.2 |
| Tls12Plus [8] |
TLS v1.2 or higher |
| Tls13 [9] |
TLS v1.3 |
|
| EnableCompressionSupport |
Enable support for gzip or deflate compression (for deflate you must turn on [Tls 1.0 Or Higher] Option on Advanced Settings - Security Protocol for HTTPS). When you check this option compressed response automatically de-compressed saving bandwidth. This option is only valid if web server supports compressed response stream. Check your API documentation for more information. |
| IgnoreCertificateErrors |
Ignore SSL certificate related errors. Example: if you getting SSL/TLS errors because of certificate expired or certificate is not from trusted authority or certificate is self-signed. By checking this option you will not get SSL/TLS error. |
| AllowUnsecureSuite |
Allow unsecure ciphers/suites and curves for SSLS/TLS communication. Use this option to communicate with web servers which needs legacy / unsecured ciphers support. This option is only trigged when you change default SSL/TLS Version on advanced settings tab. |
| UseConnection |
Use connection to pass credentials for authentication (e.g. Use UserID/Password or Use OAuth Protocol for token based approach) |
| PagingMode |
Specified how you want to loop through multiple pages returned by REST API.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| ByResponseAttribute [0] |
Response Attribute Mode - Read next page information from response |
| ByUrlParameter [1] |
Url Parameter Mode - Page number / offset passed as URL parameter (starts at 1 OR custom value in URL) |
| ByUrlPath [2] |
Url Path Mode - Page number / offset passed as URL path (starts at 0 OR custom value) |
| ByPostData [3] |
POST data Mode - Page number is passed inside POST data |
| ByUrlParameterMulti [4] |
Url Parameter Mode (Multi) - Pass Start and End Row Number in URL |
| ByResponseHeaderRfc5988 [5] |
Response Header contains Next Link - RFC 5988 (Next URL Link found in Standard Header) |
| ByResponseHeaderCustom [6] |
Response Header contains Next Link - Custom (Next URL Link found in Custom Header) |
| ByResponseHeaderContinuationToken [7] |
Response Header contains Continuation Token |
|
| EnablePageTokenForBody |
If you wish to pass extracted pagination token or current page number in the body of next request then set this option to true. You can use [$pagetoken$] and [$pagenumber$] placeholders anywhere in the Body where you wish to insert extracted Page token. If you must set encoded token then you can use <%nextlink_encoded%> inside SuffixForNextUrl Property. If you dont use SuffixForNextUrl then raw nextLink or Token will be inserted inside the body. If you dont specify [$pagetoken$] placeholder in the body then NextPage Token will be appended at the end. NextPage Token is extracted by filter expression specified using property NextUrlSuffix |
| HasDifferentNextPageInfo |
Set this to true if you wish to specify different URL, Header, Body or Filter for first page and next page (i.e. Paginated response). Some APIs like Amazon MWS, NetSuite, Zuora) you may need to set this to true. |
| PagePlaceholders |
When HasDifferentNextPageInfo=true you can set this property to indicate first page and next page. You can specify different URL, Header, Body or Filter for first page and next page (i.e. Paginated response). Use [$tag$] as placeholder anywhere in the URL, Header, Body or Filter and at runtime system will replace it with correct value (first page or next page value). Syntax to specify placeholder for first page vs next page is like a connectionstring url=FirstPageValue|NextPageValue;header=FirstPageValue|NextPageValue;body=FirstPageValue|NextPageValue;filter=FirstPageValue|NextPageValue;method=FirstPageValue|NextPageValue; You can use one or more key/value pairs to make things dynamic (e.g. url, header, body, filter or method) .For example if you have pagination in your API and First URL is http://abc.com/api/items/get and to get more records you have to call http://abc.com/api/items/getNext then you can use [$tag$] as placeholder in the URL http://abc.com/api/items/[$tag$] and specify this property with first page tag and next page tag as url=get|getNext (Tags are separated using vertical bar). |
| FirstPageBodyPart |
Use this property to set request body fragment for first page. HasDifferentNextPageInfo must be set to true to use this property. |
| NextPageBodyPart |
Use this property to set request body fragment for any request after first request. HasDifferentNextPageInfo must be set to true to use this property. |
| PagingMaxPagesExpr |
Expression to extract Maximum pages to loop through. Some APIs don't stop pagination and keep returning last page data when you try to read data after last page. Specify expression (e.g. $.page_count ) to read total pages to loop through using this property. |
| PagingMaxRowsExpr |
Expression to extract Maximum records to loop through. Some APIs don't stop pagination and keep returning last page data when you try to read data after last page. Specify expression (e.g. $.total_rows ) to read total pages to loop through using this property. This setting is ignored if you set PagingMaxPagesExpr. |
| PagingMaxRowsDataPathExpr |
When you enable PagingMaxRowsExpr (end pagination based on MaxRowCount) then you need to count records coming in each response. This expression extract all rows found under specified expression (e.g. $.orders[*] if all records found under orders node). |
| PageNumberAttributeNameInUrl |
e.g. Type page_num if URL looks like this => http://abc.com/?page_num=1&sort=true (page number via query string)
--or-- Type <%page%> if page number is inside URL path like this => http://abc.com/1/?sort=true (e.g. replace page number in url with placeholder http://abc.com/<%page%>/?sort=true)
Page number will be incremented by one for next URL until last page is reached or [Max Page Number] is reached. This parameter also controls pagination mode [ByResponseHeaderContinuationToken]. When this mode is used you can enter RESPONSE_HEADER_NAME --OR-- NEXT_QUERY_PARAM=RESPONSE_HEADER_NAME --OR-- NEXT_QUERY_PARAM=RESPONSE_HEADER_NAME(regular_expression). If NEXT_QUERY_PARAM (left side) is omitted then Response Header value is sent to next request in the same Header name. If you like to pass response header value in the next URL then use two parts (e.g. cursor=X-CONTINUE-TOKEN) ... this example will read X-CONTINUE-TOKEN header from response and pass it to next request in the URL like http://myapi.com/?cursor=[value-from-previous-response]. You can also use advanced syntax using Regular expression to extract substring from response header value (e.g. cursor=X-CONTINUE-TOKEN(\d*)) will extract only numeric part from header value. Another example is cursor=X-CONTINUE-TOKEN(^((?!null\b).)*$) ... this will return value if its other than "null" (word). For more information about using regular expression check this link https://zappysys.com/links/?id=10124 |
| MaxPageNumber |
Maximum page number until which auto increment is allowed. Type zero for no limit. Next URL contains next page number (increment by one) until last page is detected or [Max Page Number] limit is reached. |
| PagingEndRules |
Rules to end pagination. You can use XML markup to include multiple rules. Here is an example of XML with multiple rules. This will stop pagination if any of these rule matches (Status Code, Size, Error Message) <ArrayOfPagingEndRule><PagingEndRule><Mode>DetectBasedOnResponseStatusCode</Mode><StatusCode>401</StatusCode></PagingEndRule><PagingEndRule><Mode>DetectBasedOnRecordCount</Mode></PagingEndRule><PagingEndRule><Mode>DetectBasedOnResponseSize</Mode><MinBytes>3</MinBytes><MaxBytes>200</MaxBytes></PagingEndRule><PagingEndRule><Mode>DetectBasedOnResponseErrorMessage</Mode><ErrString>key not found</ErrString></PagingEndRule></ArrayOfPagingEndRule> |
| StartPageNumberVariable |
Variable name which will hold starting page number. This is ignored if you using parameter name from query string to indicate page number. |
| PageNumberIncrement |
Page counter increment. By default next page is incremented by one if this value is zero. You can also enter negative number if you want to decrease page counter. |
| PagingEndStrategy |
Specified how you want detect last page.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| DetectBasedOnResponseSize [0] |
Detect last page based on response size (in bytes) |
| DetectBasedOnResponseErrorMessage [1] |
Detect last page based on error message (sub string) |
| DetectBasedOnResponseStatusCode [2] |
Detect last page based on status code (numeric code) |
| DetectBasedOnRecordCount [3] |
Detect based on missing row (stop when no more records) |
| DetectBasedOnMultipleRules [4] |
Detect based on multiple rules (i.e. mix of status(es), size, error) |
|
| LastPageWhenConditionEqualsTo |
Condition result to compare to detect last page. Set this property to True if you want detect last page if condition is true else set this to False. |
| ResponseMinBytes |
Minimum bytes expected from response. |
| ResponseMaxBytes |
Maximum bytes from response. |
| ResponseErrorString |
Expected error message sub string from response. |
| ResponseStatusCode |
Expected status code from response when page number you trying to access not found. |
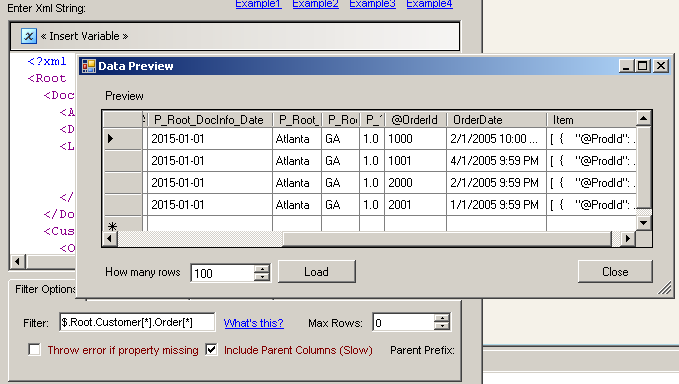
| Filter |
Enter expression here to filter data.(Example: $.Users[*].UserName ) This will fetch User names from users records |
| IncludeParentColumns |
Use this option to include parent properties (Non array) in the output along with Filtered Rows |
| IncludeParentColumnsWhenChildMissing |
By default child and parent information is not included in the output if children not found for specified expression. For example if you want to extract all orders from all customers nodes then you can type $.Customers[*].Orders[*]. This will fetch all orders from all customers. By default customers records without orders wont be included in the output. If you want to include those customers where orders not found then check this option (Output null information for order attributes). This behavior is similar to LEFT OUTER JOIN in SQL (Left side is parent, right side is child). This option is ***resource intensive*** so only check if you really care about this behavior. |
| IncludeParentColumnsWithArrayType |
Set this option to true if you want to output parent columns which are array. By default any parent column which is an array is not included in output. See also FilterForParentColumnsWithArrayType property if you set this property |
| FilterForParentColumnsWithArrayType |
Filter expression to extract value form parent |
| ParentColumnPrefix |
Prefix for parent column name. This option is only valid if you have set IncludeParentColumns=True |
| ThrowErrorIfPropertyMissing |
Throw error if property name specified in filter expression is missing. By default it will ignore any missing property errors. |
| MaxLevelsToScan |
This property how many nested levels should be scanned to fetch various properties. 0=Scan all child levels. |
| ExcludedProperties |
List comma separated property names from XML document which you want to exclude from output. Specify parent property name to exclude all child nodes. |
| LevelSeparator |
Property level separator used in generated property name (separator for outer properties - Above selected filter node). Use this if default separator is producing duplicate property name which is conflicting with existing name. |
| EnableArrayFlattening |
Enables deep array flattening for selected filtered hierarchy. When you turn on this property it will flatten each property of each array item and expose as column (e.g. If you have Filter set as $.customers[*] and for each customer you have an array of Addresses then you may see output columns like Addresses.1.City, Addresses.1.State, Addresses.2.City, Addresses.2.State .... Addresses.N.City, Addresses.N.State). You can control how many array items you want to flatten by setting MaxArrayItemsToFlatten property. |
| MaxArrayItemsToFlatten |
Maximum number of array items to flatten. inner array flattening. Adjust this property to control how many columns being generated. This option is ignored if you set EnableArrayFlattening=false |
| FileCompressionType |
Compression format for source file (e.g. gzip, zip)
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| None [0] |
None |
| GZip [1] |
GZip |
| Zip [2] |
Zip |
| TarGZip [3] |
TarGZip |
|
| ArrayTransformationType |
Array Transformation you want to apply. Useful for case when you have 2-Dimensional arrays with rows/columns in separate arrays.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| None [0] |
None |
| TransformSimpleTwoDimensionalArray [1] |
Simple 2-dimensional array (e.g. {cols:[..], rows:[[..],[..]]} ) |
| TransformComplexTwoDimensionalArray [2] |
Complex 2-dimensional array (e.g. {cols:[{..},{..}], rows:[{f:[..]},{f:[..]}] ) |
| TransformKeyValuePivot [3] |
Key/Value to Columns |
| TransformMultipleColumnsExpressions [4] |
Multiple columns using expressions |
| TransformColumnslessArray [5] |
Columnless array (e.g. [[..],[..]] ) |
| TransformJsonLineArray [6] |
JSON Lines - Single Dimension Array(s) (i.e. [..][..] ) |
| TransformPivotColumnlessArray [7] |
Pivot - Columnless array (e.g. [..] ) |
|
| ArrayTransColumnNameFilter |
Filter expression to use to extract column names for array transformation. |
| ArrayTransRowValueFilter |
Filter expression for row values (Not applicable for simple array transformation). |
| ArrayTransEnableCustomColumns |
When you have 2D array but don't have column list specified in a separate array then use this option (e.g. { arr: [[10,11],[21,22]] } ). If you selected Column less array or JSON Lines option then this property means Column Names coming from First Line of array. |
| ArrayTransCustomColumns |
When you have 2D array but don't have column list specified in a separate array then use specify column names here. Use comma separated list (e.g col1,col2,col3 ). Column name Order must match value order. |
| EnableRawOutputModeSingleRow |
Enable Raw Document Output Mode with unstructured data processing option for any format (i.e. XML, Html, Text, Json). Unlike other option EnableRawOutputMode, this option doesn't invoke parser to extract documents by finding row terminator. It will source string as row value in single row/ single column. You can also define RawOutputDataTemplate along with this property (e.g. Template can be {data: [$1] } ). This will wrap response inside template string before sending to parser. |
| RawOutputDataRowTemplate |
When you enable EnableRawOutputModeSingleRow you can use this property. Template must be in JSON format (e.g. { data: [$1] } ). [$1] means content extracted using first expression or no expression (i.e. raw data). If RawOutputFilterExpr contains multiple expressions (separated by || ) then you can use multiple placeholders (i.e. [$1], [$2]...[$N]). RawOutputFilterExpr can have JsonPath, XmlPath, RegEx (set RawOutputExtractMode). If you using this along with SaveContentAsBinary then make sure to set ResponseDataFile else Template will not be invoked. |
| DateFormatString |
Specifies how custom date formatted strings are parsed when reading JSON. |
| DateParseHandling |
Specifies how date formatted strings, e.g. Date(1198908717056) and 2012-03-21T05:40Z, are parsed when reading JSON.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| None [0] |
Keep date as string |
| DateTime [1] |
Convert to DateTime (Timezone lost) |
| DateTimeOffset [2] |
Convert to DateTimeOffset (Preserve Time zone) |
|
| FloatParseHandling |
Specifies how decimal values are parsed when reading JSON. Change this setting to Decimal if you like to have large precision / scale.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| Double [0] |
Default (Double [~15-17 digits]) |
| Decimal [1] |
Decimal (High Precision / Scale [~28-29 digits] ) |
|
| IndentOutput |
Indent JSON output so its easy to read. |
| OutputRawDocument |
Output as raw JSON document rather than parsing individual fields. This option is helpful if you have documents stored in a file and you want to pass them downstream as raw JSON string rather than parsing into columns. |
| ConvertFormat |
Output convert raw XML document to JSON (Recommended). This option is ignored if OutputRawDocument=false. Once you do that any further parsing downstream must use JSON Parser rather than XML Parser. |
| OnErrorOutputResponseBody |
When you redirect error to error output by default you get additional information in ErrorMessage column. Check this option if you need exact Response Body (Useful if its in JSON/XML format which needs to be parsed for additional information for later step). |
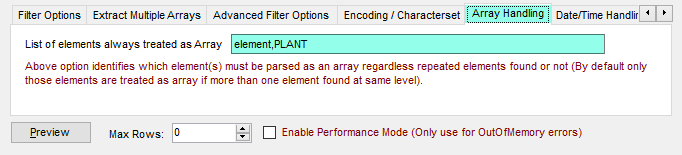
| ElementsToTreatAsArray |
Comma separated element names which you want to treat as Array regardless how many times element repeats at the same level. By default only those elements are treated as array if element appears more than once at the same level. |
| EnablePerformanceMode |
Enables memory optimized mode. You may lose certain functionality when you turn on this. Only turn on this feature if you getting out of memory error. |
| OutputFilePath |
Set this option to true if you want to output FilePath. This option is ignored when you consume DirectValue or data from Url rather than local files. Output column name will be __FilePath |
| OutputFileName |
Set this option to true if you want to output FileName. This option is ignored when you consume DirectValue or data from Url rather than local files. Output column name will be __FileName |
| EnableArchiveFile |
Set this option to true if you want to move processed file to archive folder. |
| ArchiveFolderPath |
Folder path where you want to move processed file. |
| OverwriteFileInArchiveFolder |
Folder path where you want to move processed file. |
| ArchiveFileNamingConvention |
File naming convention for archived file. By default it will use same name as original source file processed. But you can control naming format using {%name%} and {%ext%} placeholders. Examples: {%name%}_{%timestamp%}_processed{%ext%} or {%name%}{%ext%}.{{System::ContainerStartTime,yyyyMMdd_HHmmss_fff}} |
| EnablePivot |
When this property is true then Column is converted to Row. Pivoted names will appear under Pivot_Name column and values will appear under Pivot_Value field. |
| IncludePivotPath |
When this property is true then one extra column Pivot_Path appears in the output along with Pivot_Name and Pivot_Value. This option is really useful to see parent hierarchy for pivoted value. |
| EnablePivotPathSearchReplace |
Enables custom search/replace function on Pivot_Path before final value appears in the output. This option is only valid when IncludePivotPath=true. |
| PivotPathSearchFor |
Search string (static string or regex pattern) for search/replace operation on Pivot_Path. You can use --regex suffix to treat search string as Regular Expression (e.g. MyData-(\d+)--regex ). To invoke case in-sensitive regex search use --regex. This option is only valid when EnablePivotPathSearchReplace=true. |
| PivotPathReplaceWith |
Replacement string for search/replace operation on Pivot_Path. If you used --regex suffix in PivotPathSearchFor then you can use placeholders like $0, $1, $2... anywhere in this string (e.g. To remove first part of email id and just keep domain part you can do this way. Set PivotPathSearchFor=(\w+)@(\w+.com)--regex, and set current property i.e. PivotPathReplaceWith=***@$2 ). This option is only valid when EnablePivotPathSearchReplace=true. |
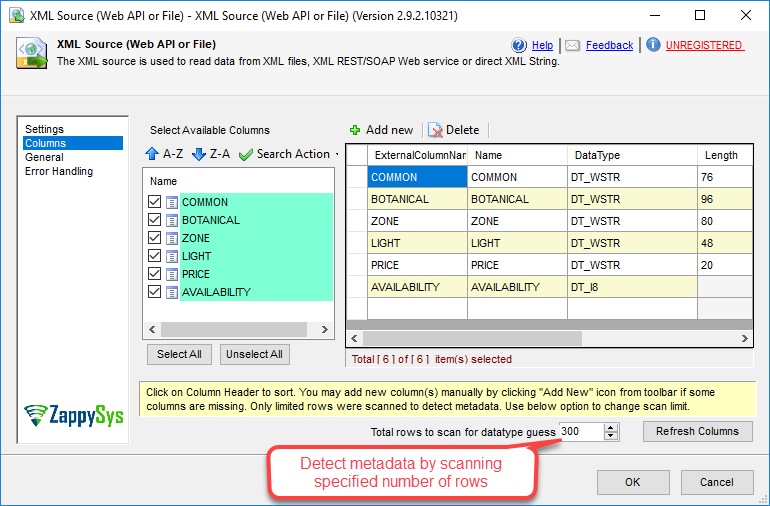
| MetaDataScanMode |
Metadata scan mode controls how data type and length is determined. By default few records scanned to determine datatype/length. Changing ScanMode affects length/datatype accuracy.
Available Options (Use numeric value listed in bracket if you have to define expression on this property (for dynamic behavior).
| Option |
Description |
| Auto [0] |
Auto |
| Strict [1] |
Strict - Exact length |
| Guess2x [2] |
Guess2x - 2 times bigger |
| Guess3x [3] |
Guess3x - 3 times bigger |
| Guess4x [4] |
Guess4x - 4 times bigger |
| TreatAsUnicodeString [5] |
Set all columns as string |
| Guess10x [6] |
Guess10x - 10 times bigger |
| TreatStringAsMaxLength [7] |
Set string columns with MAX Length - i.e. DT_WSTR(4000) |
| TreatStringAsBlob [8] |
Set string columns as BLOB - i.e. DT_NTEXT |
|
| MetaDataCustomLength |
Length for all string column. This option is only valid for MetaDataScanMode=Custom |
| MetaDataTreatStringAsAscii |
When this option is true, it detects all string values as DT_STR (Ascii) rather than DT_WSTR (Unicode) |